本科毕设参考文献笔记
核心:大模型辩论

发表于2024年。
本文提出一种可解释性有害表情包检测方法,通过对无害和有害立场的冲突理由进行推理实现检测目标。具体而言,受大型语言模型(LLMs)在文本生成和推理方面的强大能力启发,我们首先引导大型语言模型进行多模态辩论,生成基于对立观点的解释;随后,微调一个小型语言模型作为辩论评判器进行有害性推断,以促进有害性理由与表情包内在多模态信息的融合。
之前的研究将模因文本和图像标题作为掩码语言建模(Masked Language Modeling)的提示词(Prompt),以此来预测模因是否有害。后续有一项研究 专门定制了额外的手工设计问题,作为冻结参数的预训练视觉-语言模型的提示词,旨在进一步改善图像描述生成,从而提升模因分类的性能。 然而,这些有害模因检测方法仅以“黑盒”(Black-box)的方式捕捉表层的有害模式来进行分类 ,这种做法往往忽略或过度简化了用于解释最终有害性预测的支撑依据。 即以前的方案缺少对有害性预测的解释能力,无法提供有害性判断的依据。
解释模因需要对常识以及文化背景有深入理解,于是使用了llms,但由于llms的差异性,引入了多模态辩论机制。最后将辩论结果输入到一个小型的评判器中进行有害性分类。
利用小模型(T5)的相对位置编码(Relative Position Encoding)特性。这种排序方式让小模型能够感知 LLM 的倾向。这迫使小模型在微调时,重点关注那些被 LLM 误判的困难样本(即 LLM 推荐了前面的理据,但真实标签是相反的),从而学习修正 LLM 的错误认知
小模型如何理解图片和文本的交互:
文本编码:使用 Transformer 编码器(基于 T5)处理拼接后的文本序列 。
视觉特征:使用参数冻结的预训练 Vision Transformer (ViT) 提取图像特征 。
交叉注意力机制 (Cross-Attention):在编码器的每一层,使用文本作为 Query,图像作为 Key 和 Value 进行注意力计算 。
这使得文本中的辩论逻辑能够主动“关注”图像中的视觉证据,实现深度的多模态交互 。
训练目标
生成式分类:模型采用生成式架构(Decoder),目标是直接生成预测的标签文本(如 "harmful" 或 "harmless"),而不是输出分类概率 。 损失函数:使用生成的标签与真实标签之间的交叉熵损失(Cross-Entropy Loss)进行训练 。
一句话总结: 3.4节提出用一个轻量级模型来做最终决策,通过交叉注意力融合视觉信息,并利用动态排序策略吸取大模型的推理成果并修正其错误,从而实现高效且精准的有害模因检测。
基于多模态大语言模型的攻击性模因解释生成方法
核心:基于GPT3.5的数据补强以及使用LLaMA-Adapter V2进行多模态输入

发表于2024年。
以 LLaMA-Adapter V2 作为多模态大语言模型基座,使用 CLIP 作为冻结的图像编码器提取图像的全局视觉特征,通过投影层与 Adapter 将视觉特征映射到 LLaMA 可理解的特征空间,从而实现视觉信息与语言模型的对齐。同时,利用 GPT-3.5 在训练前对多个模因数据集进行解释增强,构建指令微调数据集,最终通过指令微调训练 LLaMA-Adapter V2,使模型具备攻击性模因解释生成能力。
目前可以获得的开源数据集只有2个,分别是HatReD[5]仇恨模因解释生成数据集(3 228个样本)和MemeCap[19]模因隐喻解释生成数据集(6 384个样本). 有限的训练数据可能不足以让大模型学到模因的隐喻表达手法和多模态互补的攻击性特征. 而其他的开源模因数据集主要针对分类任务构建,缺少相应的模因解释,比如对隐喻式进行分类的METMeme[34]数据集和Propaganda[35]数据集,以及识别有害模因的HarMeme[36]数据集和讽刺模因的SarcasmMeme[37]数据集. 这些数据集有人工标注的不同属性特征,比如对应分类任务的类别、情感和攻击对象等特征. 本文结合人工标注的属性特征和多模态模型生成的模因图片描述信息,利用GPT-3.5强大的文本推理分析能力,自动生成开源模因数据集的文本解释,使其与模因的隐喻识别和攻击性概念对齐. 具体的数据集列表如表1所示 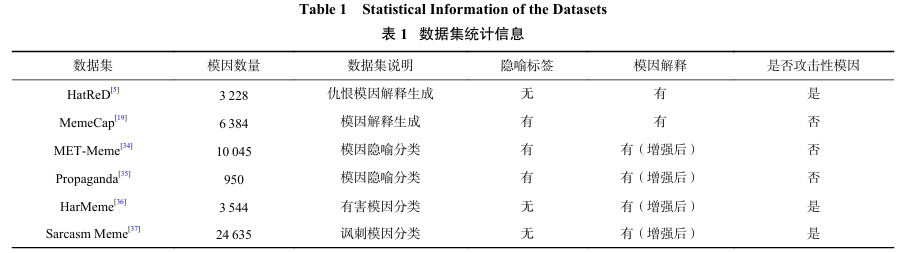
数据增强使用Blip-2和LLaMA Adapter V2的生成结果拼接喂给gpt3.5 
采用了自动评估和GPT-4专家评估相结合的方法. 自动评估指标通过可计算的量化方式评估生成文本和参考文本之间的相似度. 专家评估指标从生成解释的正确性、流畅性、背景知识分析能力、隐喻识别能力和客观性5个方面评估生成质量. 采用了自然语言生成任务中常见的度量标准,其中包括基于词语相似性的N-gram匹配以及基于嵌入的语义相似性度量.
原始图片
↓
CLIP(视觉编码器)
→ 输出:视觉特征向量(不是文字)
↓
投影层(维度 / 空间调整)
→ 把视觉特征变成“尺寸合适”的向量
↓
Adapter(注入到 LLaMA 内部)
→ 让这些向量真正参与 LLaMA 的推理过程
↓
LLaMA(语言模型)
→ 生成文字解释Prompting for Multimodal Hateful Meme Classification
核心:提示词工程,图像转文本

发表于2022年。
理想情况下,可以利用一个明确的外部知识库来补充仇恨 meme 中的上下文和文化信息。然而,目前还没有已知的明确外部知识库能够提供此类仇恨言论的上下文信息。为了填补这一空白,本文提出了 PromptHate,这是一种简单但有效的基于提示词的模型,它通过提示预训练语言模型(PLMs)来进行仇恨 meme 分类。具体来说,构建了简单的提示词,并提供了一些上下文示例,以利用预训练的 RoBERTa 语言模型中的隐含知识进行仇恨 meme 分类。
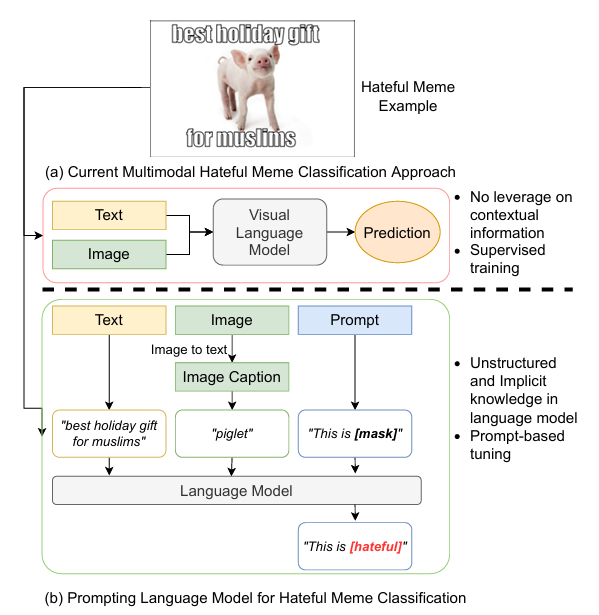
为了利用 PLM 进行多模态仇恨表情包分类,首先将表情包中的图像转换为 PLM 可接受的文本输入。使用开源 Python 工具 EasyOCR² 提取表情包中的文本,随后利用 MMEditing³ 对图像进行修移除文本。接着,使用预训练的图像描述生成模型 ClipCap生成高质量的描述,其生成的描述通常刻画图像中占主导地位的物体或事件。我们将这些生成的图像描述作为 PromptHate 模型的输入。除了图像描述之外,我们还利用 Google Vision Web Entity Detection API⁴ 以及预训练的 FairFace 分类器(Kärkkäinen and Joo, 2019)来提取表情包中的实体信息,以及当图像中包含人物时的相关人口统计学信息。这些提取到的实体信息和人口统计信息作为补充信息,与图像描述一起组合后输入到 PLM 中
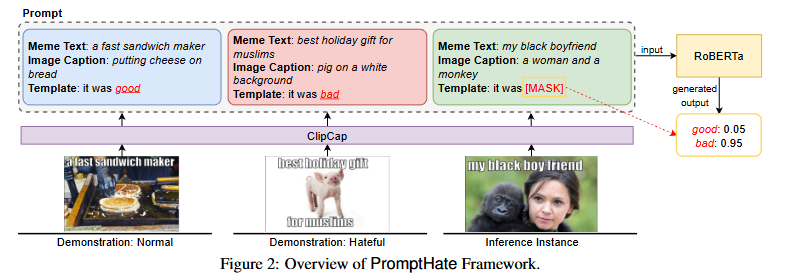


在提示词的示例选择中提供多个选择,最后取均值 
数据集:Facebook仇恨模因数据集(FHM)(Kiela等人,2020年)和有害模因数据集(HarM)(Pramanick等人,2021a)。由于测试集没有公开标签,作者使用 dev-seen 作为验证和评估集。
测评指标:受试者工作特征曲线下面积(AUROC,简称 AUC)和准确率(Acc)。为了使报告结果更加可靠,我们测量了模型在十个随机种子下的平均表现 。所有模型都使用相同的一组随机种子
提示词工程
标签词(Label Words)设计实验

引入仇恨目标信息(Target Information)实验

错误分析
图像描述(caption)通常能够概括图像的主要内容,但在仇恨表情包检测任务中,它们可能会忽略一些关键属性。例如,图像描述无法捕捉到诸如“Jesus(耶稣)”这样的重要信息。这类缺失的信息在一定程度上可以通过增强的图像标签(即表情包中的实体信息和人口统计信息)进行补充。
然而,我们也发现,即便在加入了额外的图像描述信息之后,PromptHate 仍然会对这些表情包做出错误预测。
造成错误预测的原因可能有多方面。首先,所提供的信息仍然可能缺乏足够的上下文。例如,在第二个表情包中,图像描述及其补充信息都未能体现出“咬”或“吃”的动作,因此 PromptHate 无法理解该表情包是在嘲讽亚洲人“吃狗”的刻板印象,从而未能判断其具有仇恨性。
其次,模型本身可能学习到了某些偏见。例如,PromptHate 可能会因为最右侧表情包中出现了彩虹旗(LGBT 群体的象征)而将其预测为仇恨内容,因为这一符号经常出现在攻击 LGBT 群体的表情包中。
最后,对于某些表情包而言,理解其仇恨语境可能需要更高级的推理能力。
在某些情况下,尽管PromptHate能够利用预训练语言模型(PLM)中的隐含知识来改进仇恨表情包分类尽管如此,它仍然缺乏对上下文信息进行高级推理以得出正确预测的能力。我们还观察到,PromptHate可能会从训练数据中学习到偏见,因此可能需要去偏技术来提高其性能。
Decoding the Underlying Meaning of Multimodal Hateful Memes
核心:创建HatReD数据集
发表于2023年
仇恨表情包解释方法缺乏的一个主要原因是,目前没有包含用于基准测试或训练的真实解释的仇恨表情包数据集。直观地说,有了这些解释,可以指导和帮助内容审核人员理解并移除被标记的仇恨表情包。本文通过引入“带原因的仇恨表情包数据集(HatReD)”来填补这一研究空白,该数据集是一个新的多模态仇恨表情包数据集,标注了潜在的仇恨语境原因。还定义了一项新的条件生成任务,旨在自动生成潜在原因来解释仇恨表情包,并在此任务上建立最先进的预训练语言模型的基准性能。通过分析在已知和未知领域解释表情包时新条件生成任务所面临的挑战,进一步证明了HatReD的实用性。数据集和基准模型可在以下网址获取:https://github.com/Social-AI-Studio/HatRed
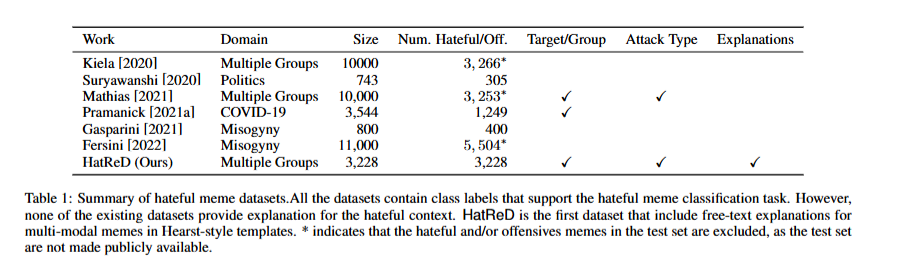
HatReD 数据集包含 3,304 条针对 3,228 个仇恨表情包的已标注原因。由于有些表情包会攻击多个社会群体,因此可能对应多个标注原因。解释文本的最小长度为 5,平均长度为 13.62,最大长度为 31。 标注原因依据以下标准进行评价: 流畅度(Fluency):使用 5 点李克特量表对原因在结构和语法上的正确性进行评分。 1 分:原因难以阅读,存在大量语法错误; 5 分:原因表述良好,无语法错误。 相关性(Relevance):使用 5 点李克特量表对原因与隐含仇恨言论之间的相关性进行评分。 1 分:原因未能正确反映隐含的仇恨言论; 5 分:原因能够准确反映隐含的仇恨言论。
4. 模型的结构与训练 (Hateful Memes Explanation)

纯文本 PLMs:使用了 T5 、RoBERTa 和 GPT2 。由于 GPT2 是仅解码器(decoder-only)架构,采用 RoBERTa 作为其编码器 。
视觉-语言 (VL) PLMs:以 VL-T5 和 VisualBERT 为基准。由于 VisualBERT 是仅编码器(encoder-only)架构,在两种不同的设置中分别使用 RoBERTa 和 GPT2 作为其解码器 。这些 PLMs 的评估为这个新的仇恨模因解释任务建立了基准 。
将模型置于序列到序列(Seq2Seq)架构中,并在每个解码器块中添加随机初始化的交叉注意力层 (cross-attention layers) 。通过交叉注意力层反向传播的训练误差会微调权重,从而对齐模型的特征空间
自动评估:我们采用了自然语言生成任务中常用的指标:(1) 用于词汇相似度的 N-gram 匹配(BLEU 和 ROUGE-L 及其调和平均数);(2) 用于语义相似度的基于嵌入的指标(BERTScore 的精确度、召回率和 F1 值)。
人工评估:我们招募人工评估员从两个方面评估生成的原因:流畅性 (Fluency) 和 相关性 (Relevance) 。评估员使用第 3.1 节中描述的李克特量表(Likert scales)进行打分 。为了减轻位置偏差,我们以乱序呈现生成的原因 。
为了进一步评估 HatReD 在解释仇恨模因方面的实用性,我们进行了一项领域适应 (Domain Adaptation) 实验:模型在 HatReD 上训练,但在一个未见过的数据集上进行测试 。基准模型能够生成流畅的原因,但在相关性得分上较低 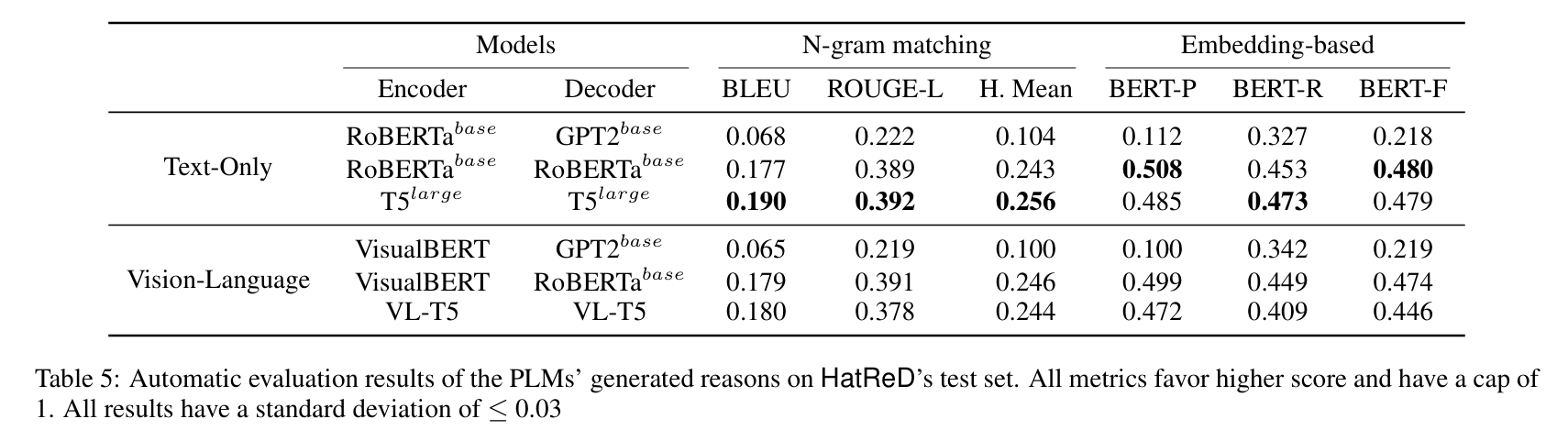
VisualBERT-RoBERTa 的错误可能是由于模型无法关联不同模态的信息,或无法理解详细的视觉信息(如该年长男子是白人) 拥有可靠的视觉信息提取器很重要 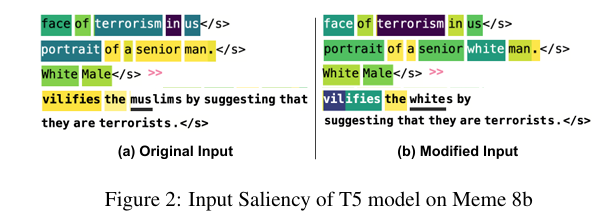
在处理新领域的模因时,生成的原因可能不准确 。例如,T5 模型对模因 9c 产生了幻觉 (hallucinates),暗示跨性别女性是性对象,尽管图文中并无此迹象 
Mapping Memes to Words for Multimodal Hateful Meme Classification
核心:文本反转
发表于2023年 。
以 CLIP (ViT-L/14) 作为视觉-语言骨干模型,提出了名为 ISSUES 的方法。该方法创新性地将文本反转(Textual Inversion)技术应用于分类任务 ,利用预训练的 SEARLE 网络 将模因图像映射为 CLIP 文本嵌入空间中的“伪词”(pseudo-word token),从而将视觉信息“注入”到文本特征中,增强了多模态语义表达 。同时,鉴于模因中图文往往存在反讽或语义冲突,直接使用 CLIP 的对齐空间不佳,因此通过训练线性投影层(Linear Projections)来解耦(Disentangle)图像和文本的特征空间 ,最终通过 Combiner 网络融合特征并由 MLP 完成分类 。
使用的数据集主要包括 Hateful Memes Challenge (HMC) 和 HarMeme 。HMC 数据集(8500个训练样本)包含精心设计的“干扰项”(confounders),即图像或文本单看无害,结合后才构成仇恨,这对模型的跨模态推理能力提出了极高挑战 。HarMeme 则是与 COVID-19 相关的真实世界模因数据。为了适应这些挑战,文章采用了两阶段训练策略 :第一阶段仅训练视觉投影层以适应模因视觉特征;第二阶段引入文本反转,联合训练文本投影层、Combiner 和分类器,使模型能够捕捉细微的图文交互语义 。
具体的模型数据流如下:
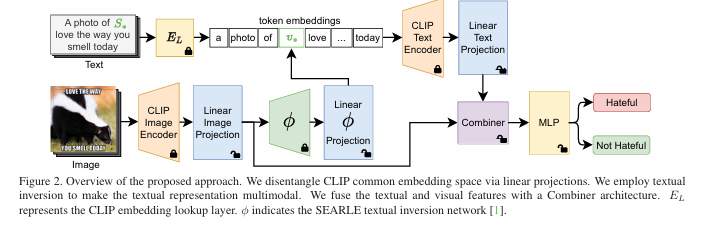
原始图片 + 原始文本
↓
分支1:文本增强(Textual Inversion)
→ 图片输入 SEARLE 网络(冻结)
[cite_start]→ 输出:伪词 token (S_*) [cite: 105]
[cite_start]→ 构造 Prompt: "a photo of S_*, {meme text}" [cite: 105]
→ 输入 CLIP 文本编码器 + 线性文本投影层
→ 输出:增强后的多模态文本特征
↓
分支2:视觉特征
→ 图片输入 CLIP 视觉编码器 + 线性视觉投影层
→ 输出:解耦后的视觉特征
↓
Combiner(融合网络)
[cite_start]→ 融合上述两路特征 [cite: 117]
↓
MLP(分类器)
[cite_start]→ 输出:Hateful / Not Hateful [cite: 122]采用了 Hateful Memes Challenge 竞赛的标准评估指标,主要包括 AUROC (Area Under the Receiver Operating Characteristic curve) 和 准确率 (Accuracy) 。AUROC 是主要指标,用于评估模型在正负样本区分上的鲁棒性,特别是在面对含有“干扰项”的难例时。通过消融实验(Ablation Study),验证了 Combiner 网络、两阶段训练和文本反转技术均对性能提升有显著贡献 。
基于对比语言图像预训练的情感增强仇恨模因检测
核心:情感增强、图像描述监督、人像属性提取

发表于2024年
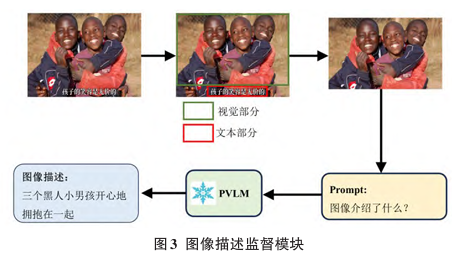
以 Chinese-CLIP 作为视觉-语言骨干模型,提出了名为 E2TC (Emotion-enhanced Transformer model based on CLIP) 的方法。该方法针对中文仇恨模因检测中隐式仇恨难以识别的问题,创新性地引入了情感增强机制(Emotion Enhancement)。模型利用 ResNet50 和 RoBERTa 分别提取图像和文本中的情感特征,并将其显式融合到 CLIP 提取的特征中,以增强模型对情感倾向的感知 。此外,考虑到仇恨模因常针对特定群体,设计了图像人物属性提取模块,提取种族、性别、年龄等信息作为额外先验知识 。为了防止模型仅关注局部特征而过拟合,还设计了图像描述监督模块(Image Caption Supervision),利用冻结的大模型(BLIP-2)生成的描述作为监督信号,强制模型关注图像的全局语义 。
使用的数据集主要包括自建的 CHmemes 以及英文公开数据集 Hateful Memes (FHM) 和 HarMeme 。CHmemes 是首个中文仇恨模因数据集(4254张图像),由微博爬取的真实数据(2754张)和 FHM 数据集的翻译版本(1500张非仇恨图像以平衡样本)组成,涵盖了种族、性别、地域等多个仇恨主题 。模型采用了联合训练策略,损失函数由两部分组成:用于分类任务的二元交叉熵损失和用于图像描述生成分支的交叉熵损失,两者加权结合进行优化 。
具体的模型数据流如下: 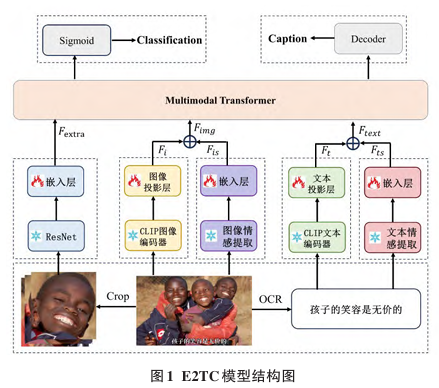
原始图片 + 原始文本
↓
分支1:特征提取与对齐
[cite_start]→ 图片输入 Chinese-CLIP 视觉编码器 → 投影层 → 视觉特征 F_i' [cite: 75, 80]
[cite_start]→ 文本输入 Chinese-CLIP 文本编码器 → 投影层 → 文本特征 F_t' [cite: 78, 83]
↓
分支2:辅助特征增强
[cite_start]→ 图片输入 情感提取模型 (ResNet50) → 图像情感特征 F_is [cite: 108]
[cite_start]→ 图片输入 属性提取模型 (ResNet34) → 人脸属性特征 (种族/性别/年龄) F_extra [cite: 87, 95]
[cite_start]→ 文本输入 情感提取模型 (RoBERTa) → 文本情感特征 F_ts [cite: 109]
↓
特征融合
[cite_start]→ F_i' + F_is → 情感增强的图像特征 F_img [cite: 111]
[cite_start]→ F_t' + F_ts → 情感增强的文本特征 F_text [cite: 111]
[cite_start]→ 拼接 [F_img, F_text, F_extra] 输入 Multimodal Transformer [cite: 112]
↓
双分支输出
[cite_start]→ 分支A (分类): Transformer 输出 → Sigmoid → Hateful / Non-hateful [cite: 47]
[cite_start]→ 分支B (监督): Transformer 输出 → Decoder → 生成图像描述 (与 BLIP-2 结果计算 Loss) [cite: 119]采用了仇恨模因检测任务的标准评估指标,主要包括 AUROC 和 准确率 (Accuracy) 。在 CHmemes 数据集上,E2TC 模型取得了 77.67% 的 AUROC 和 72.71% 的准确率,均优于 BERT、VisualBERT、Hate-CLIPper 等对比模型,并在 FHM 和 HarMeme 数据集上也展现了良好的泛化性 。
定性分析方面,文章对比了 E2TC 与 Pro-Cap 模型。结果显示,E2TC 由于引入了显式情感特征,能够纠正大模型因偏见导致的错误预测(例如正确识别出“面带笑容的穆斯林”模因属于非仇恨,而 Pro-Cap 因偏见误判为仇恨) 。同时,文章也分析了错误案例,指出模型在面对需要复杂逻辑推理(如“治疗同性恋”)或长尾分布的人物属性(如变性人)时仍存在不足 。
loss设计: 
Towards Comprehensive Detection of Chinese Harmful Memes

核心:构建了TOXICN MM 数据集,提出了MKE多模态检测器,使用了大模型进行知识挖掘
发表于2024年
爬取微博和贴吧整理了 TOXICN MM 数据集,以下是数据集的流程。 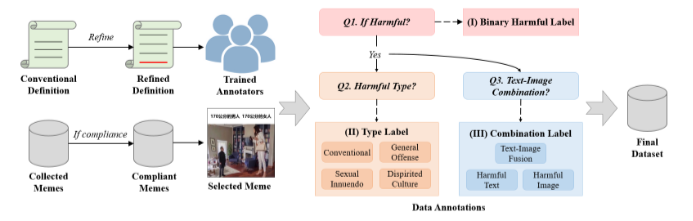
提出了中国有害模因的定义: 中国有害模因是由图像和中文嵌入文本组成的多模态单元,它们具有对个人、组织、社区、社会群体或整个社会造成伤害的潜在可能。这些模因的范围很广,既包括针对特定社会实体延续有害刻板印象的冒犯或玩笑,也包括那些更加隐晦、宽泛但仍具有潜在危害的模因。值得注意的是,中国有害模因的制作和传播可能是有意的,也可能是无意的。它们通常反映并强化了中国互联网上潜在的负面价值观和文化态度,从法律或道德角度来看,这些都是有害的。
主要包括针对性有害内容(Targeted Harmful)、一般冒犯(General Offense)、性暗示(Sexual Innuendo)以及丧文化(Dispirited Culture) 针对性有害表情包表达对特定个人或社会群体的厌恶、偏见或刻板印象。相比之下,一般性冒犯表情包包含讽刺或粗鲁的内容,但没有特定的目标。性暗示指的是暗示性意图以激起性兴奋的表情包(Bell,1997)。在此,我们将包含暗示性元素但不涉及性别歧视或性侵犯的表情包标记为此类样本,以将其与针对性有害表情包区分开来。而颓废文化的特点是融合了颓废和绝望的情绪,传递出自我否定的态度(Dong等人,2017)。
检测器结构: 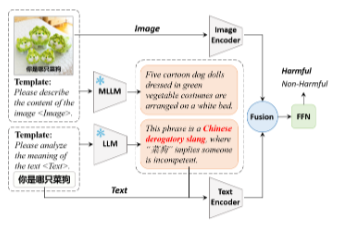
交叉注意力: 
融合与拼接: 
评判标准: 采用精确率(((P)))、召回率(((R)))和宏(F_{1})分数(((F_{1})))作为指标。报告了有害 memes 以及每种有害类型的(F_{1})。分别使用CLIP以及RoBERTa和ViT的融合模型作为MKE的骨干网络,并使用GPT-4生成增强型字幕。对于传统的预训练语言模型,我们对其参数进行微调,并根据测试集结果选择性能最佳的模型。对于大型语言模型,我们在零样本场景下评估其性能
基线模型(如 GPT-4, CLIP 等)容易犯的两类错误:良性信息的干扰、文化背景知识的缺失
SCARE: ANovel Framework to Enhance Chinese Harmful Memes Detection
核心:数据增强与模态内、模态间对比
发表于2024年
构建了一个名为 CHMEMES 的中文有害模因检测数据集 提出了一种多模态框架——语义对比对齐框架(SCARE),它能够充分表示跨模态和模态内的信息 引入了跨模态对比对齐目标,以最大化图像和文本之间的互信息 提出了一种简单而高效的视觉提示微调(Vision Prompt Tuning)范式,用于参数高效的有害模因检测
选择主流中文社交平台作为数据源,如百度、QQ、微信和微博 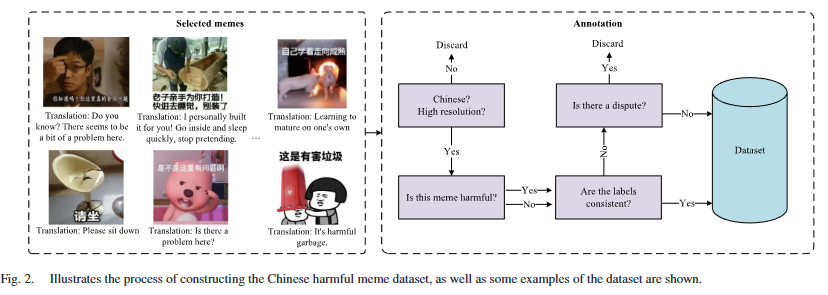
SCARE结构 核心思想是:不仅要理解图像和文本各自的含义(单模态),还要通过“对比学习”和“动量更新”来强行对齐它们之间的关系(跨模态),同时使用“视觉提示”来降低训练成本。 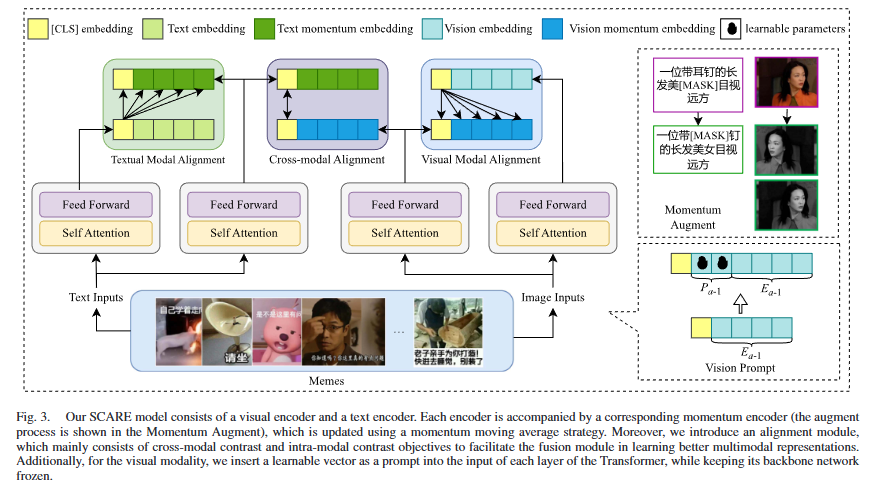
视觉提示微调 (Vision Prompt Tuning): 在传统的微调中,通常会更新整个视觉模型的参数,计算量巨大。SCARE 选择冻结(Freeze)视觉主干网络,只在每一层的输入中插入一小段可学习的参数(Learnable Parameters)让模型在不改变原有大规模预训练知识的前提下,快速适应“有害模因检测”这个特定任务。
动量增强与编码 (Momentum Augment): 文本:对文本进行掩码处理(例如图中的 [MASK]),生成增强文本。 图像:对图像进行颜色抖动、灰度化等处理(如图中彩色图变黑白图),生成增强图像。 这部分网络的参数不是通过反向传播直接更新的,而是通过移动平均(Moving Average)主编码器的参数来缓慢更新,这样能提供更稳定的特征表示。
三重对齐机制 (Alignment Module): 解决“图像和文本不匹配”以及“特征理解不深”的问题 左侧:文本模态对齐 (Textual Modal Alignment) 操作:将主文本编码器的输出(浅绿色)与动量文本编码器的输出(深绿色)进行对比。 目的(模态内对比):确保文本特征在自身模态内部是鲁棒的,即无论文本怎么由于掩码(Mask)而缺失,模型都能理解其核心语义。
右侧:视觉模态对齐 (Visual Modal Alignment) 操作:将主视觉编码器的输出(浅蓝色)与动量视觉编码器的输出(深蓝色)进行对比。 目的(模态内对比):确保视觉特征在自身模态内部是鲁棒的,即使图片变成了黑白或被裁剪,模型提取的语义应该保持一致。
中间:跨模态对齐 (Cross-modal Alignment) 操作:连接了文本的 [CLS] token(黄色块)和视觉的 [CLS] token(黄色块)。箭头是双向的。 目的(跨模态对比):这是为了拉近图像和文本在语义空间中的距离。它强制模型去理解:“这张图”和“这句话”在一起时是什么意思?如果它们是匹配的(正样本),特征应靠得更近;如果不匹配,应推得更远。
公式: 
用准确率 (Accuracy, Acc.) 和 受试者工作特征曲线下面积 (AUROC) 指标进行评估 

基于因果掩码控制与反事实干预机制融合的多模态仇恨模因检测
核心:因果掩码控制(CMCM)与反事实干预机制(CFIM)
发表于2025年
使用基于多模态孟加拉语仇恨模因数据集MUTE和多模态英语仇恨模因数据集MultiOFF上进行实验验证
构建了因果掩码控制机制模块,利用可学习因果掩码在跨模态因果层中定向建模图文特征依赖关系,有效地捕捉模态信息中的潜在因果链; 提出了一种反事实干预机制,通过遮蔽单元并量化预测概率变化量,以甄别对仇恨语义传播具有显著因果效应的关键路径节点
由特征编码、因果掩码控制机制、反事实干预机制及特征融合与解码四个核心模块构成 采用 ResNet50预训练模型提取图像视觉特征,使用BiLSTM编码器捕捉文本语义特征 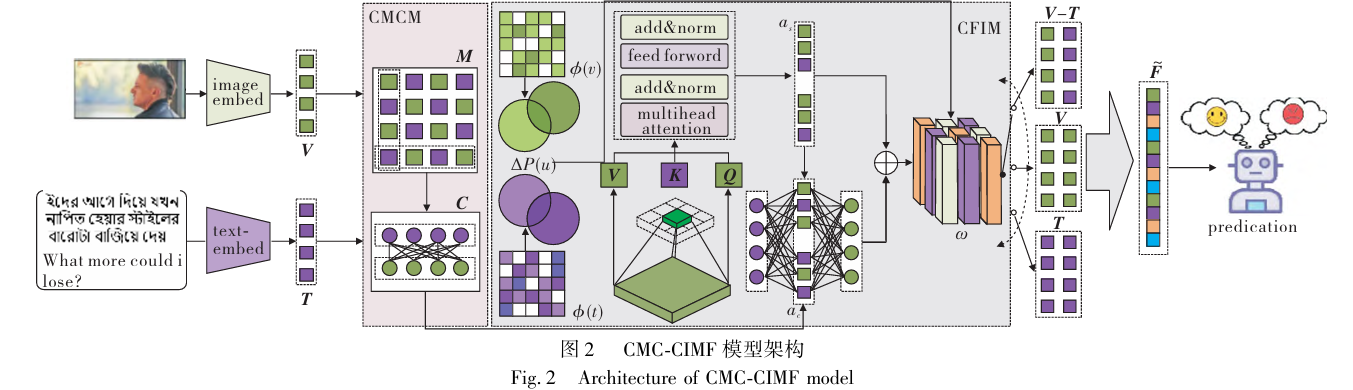


基准模型: 图像模态:ResNet50 (微调版 FT 和 重训练版 RT) 。VGG16 。ViT (Vision Transformer) 文本模态:BiLSTM 。BiLSTM + Attention (引入注意力机制) 。BERT 系列:包括多语言版的 m-BERT 和跨语言的 XLM-R,用于处理多语言混合样本 多模态模型:VisualBERTCOCO、CLIP、ALBEF、EarlyFusion、LateFusion、AttentiveFusion、MCA-SCF
精确率(precision,P)、召回率(recall,R)、加权(F_{1})分数(weighted-(F_{1}),WF)和AUC值。本文重点关注整体加权(F_{1})分数的表现
HyperPrompt: A Hypergraph-based Prompting Fusion Model for Multimodal Hate Detection

核心:超图
发表于2025年
什么是超图: 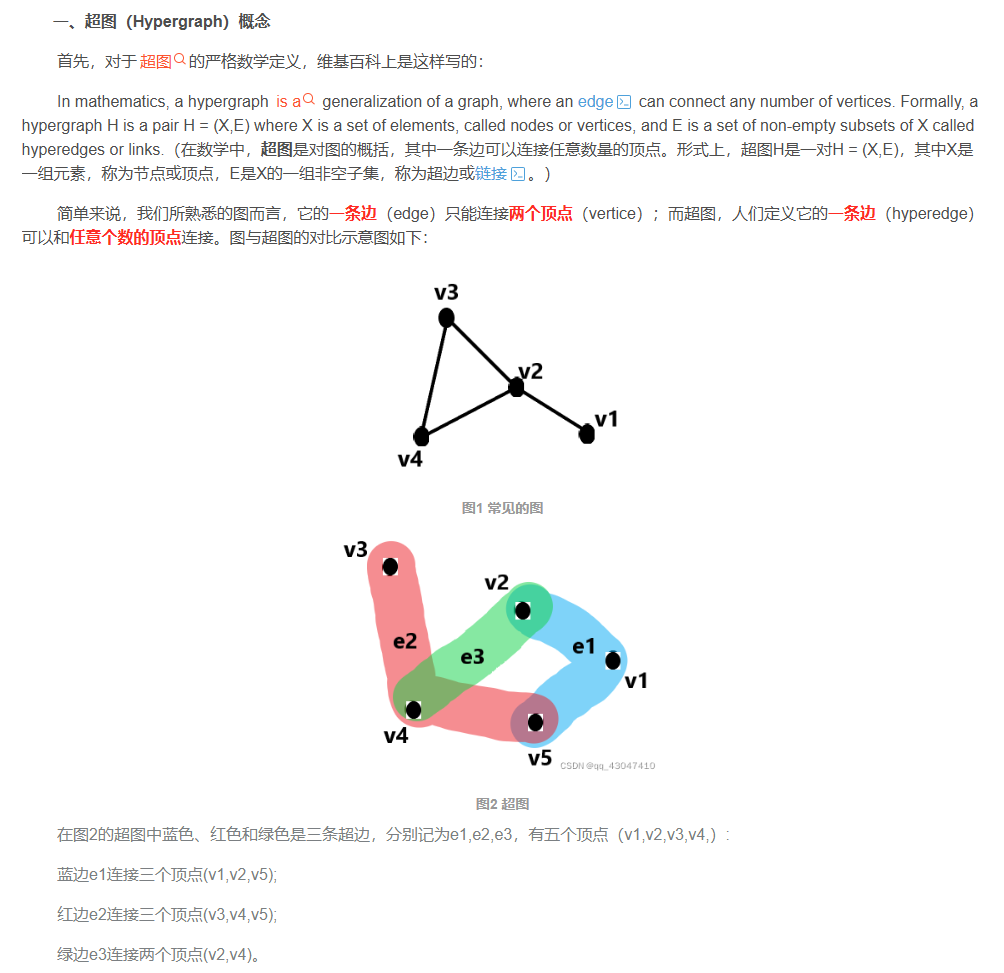
主要框架:
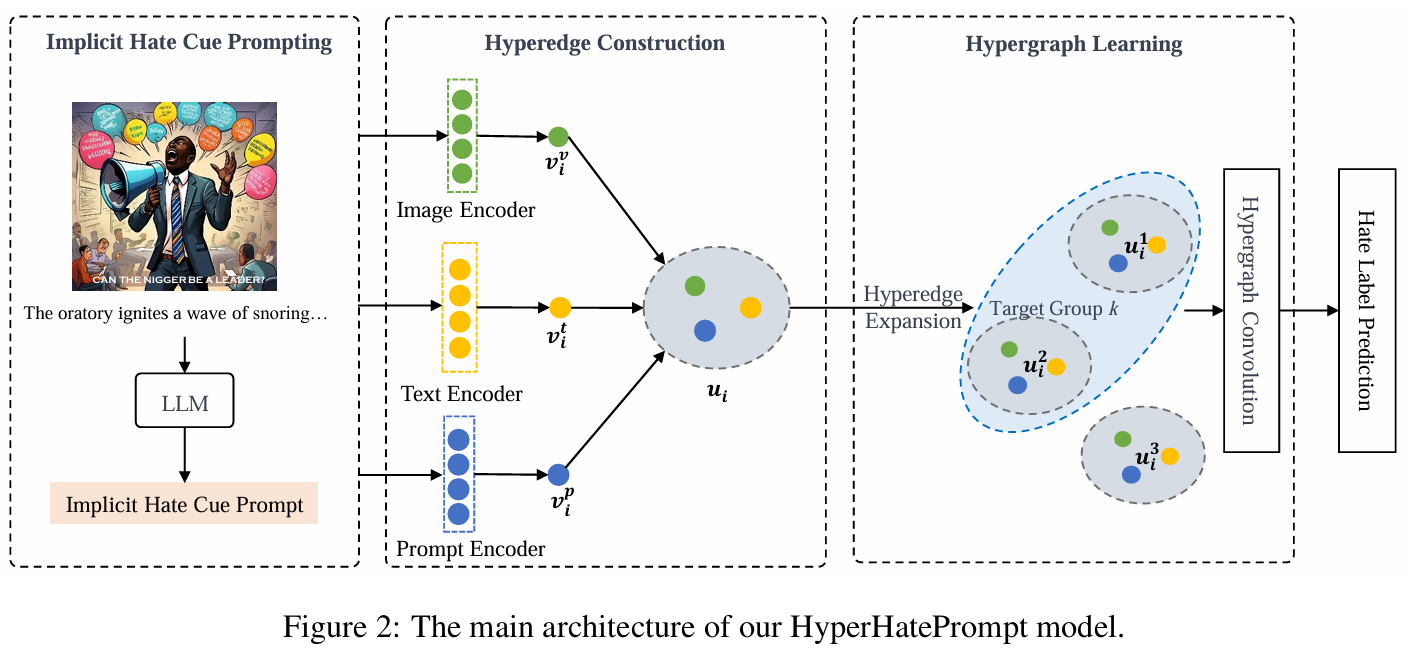 包含四个关键模块:隐性仇恨线索提示模块、超边构建模块、超图学习模块和仇恨标签预测模块 。 隐性仇恨线索提示模块:利用大语言模型(LLM)来提示文本之外的隐性仇恨线索 。 超边构建模块:聚合来自文本、图像和提示(prompts)的高表现力仇恨相关特征,并构建跨模态的高阶超边,以对跨模态诱发的仇恨进行建模 。 超图学习模块:采用一种面向多样性的超边扩展策略,并结合以仇恨目标群体为中心的超图卷积,以融合跨模态的多样化仇恨线索 。 仇恨标签预测模块:利用融合后的超图表示来预测每个数据样本的仇恨标签 。
包含四个关键模块:隐性仇恨线索提示模块、超边构建模块、超图学习模块和仇恨标签预测模块 。 隐性仇恨线索提示模块:利用大语言模型(LLM)来提示文本之外的隐性仇恨线索 。 超边构建模块:聚合来自文本、图像和提示(prompts)的高表现力仇恨相关特征,并构建跨模态的高阶超边,以对跨模态诱发的仇恨进行建模 。 超图学习模块:采用一种面向多样性的超边扩展策略,并结合以仇恨目标群体为中心的超图卷积,以融合跨模态的多样化仇恨线索 。 仇恨标签预测模块:利用融合后的超图表示来预测每个数据样本的仇恨标签 。
隐性仇恨线索提示模块
利用 LLM 显著的常识推理能力,设计了一个提示模板——“你是一个旨在检测仇恨言论的得力助手。请推断以下针对特定人口群体的文本中隐含的语义信息 。 请在回答开头使用“文本包含(the text contains)”。文本:{text} 。” 使用 GPT-3.5-turbo 模型,采用零样本生成(zero-shot generation)来生成传达隐性仇恨线索的提示
超边构建模块
利用 CLIP-ViT-B-32 模型提取图像特征,并利用 CLIP 中的 Transformer 编码器分别提取文本和提示特征。这三个特征被视为在每个模态中传达不同仇恨线索的三种类型的节点并连接每个数据样本内不同模态的节点来构建超边(跨模态) 

超图学习模块
超边扩展
通过扩展超边来增强跨不同仇恨目标群体的检测特异性,合并那些针对相同群体的超边,并离散化那些针对不同群体的超边。 为了防止节点嵌入(node embeddings)的过度平滑,我们采用了广度优先的超边扩展策略 利用超边之间的曼哈顿距离(Manhattan distance)来评估将超边 扩展到超边 的多样性差异 
在扩展后保留了初始超边,以确保同一样本内不同模态节点之间的持续连接性,从而促进对跨模态诱发仇恨的探索。 通过面向多样性的超边扩展,我们的模型增加了针对不同仇恨目标群体的超边数量,产生了一个分层的多级超边结构(hierarchical multi-level hyperedge structure)。 
超图卷积


仇恨标签预测模块

实验
在两个基准数据集上进行了实验:MMHS150K 和 MAMI 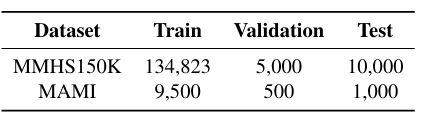
基线模型: 
参数设置: 
结论
