pi0 vla论文笔记
π0: A Vision-Language-Action Flow Model forGeneral Robot Control
面临的问题
机器人学习在数据、泛化能力和鲁棒性方面仍面临着重大障碍
通用机器人策略缺乏面对这些问题的策略。
创新点
提出了一个基于 VLM 预训练和流匹配的新型通用机器人策略架构 通过语言指令的零样本控制、微调至下游任务,以及结合输出中间语言指令的高级语义策略来执行复杂的长时段任务
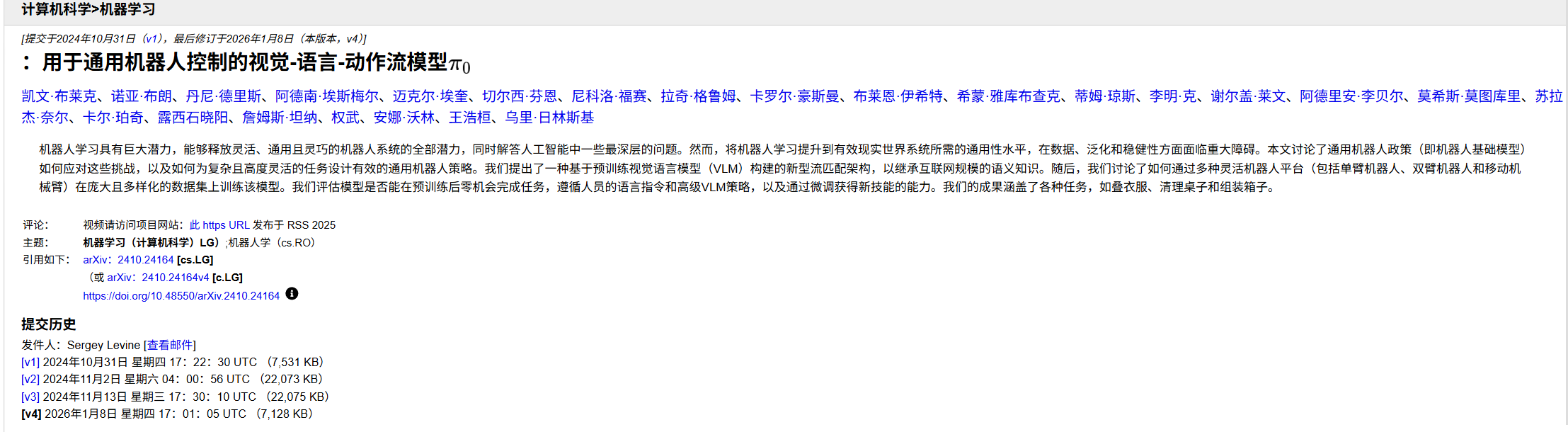
 采用预训练的视觉-语言模型(VLM)骨干网络,结合包含多种灵巧操作任务的多样化跨体数据集。通过添加一个独立的动作专家,适配机器人控制任务。该专家通过流匹配生成连续动作,从而实现精准且流畅的操作技能。随后,可通过提示词实现该模型的零样本控制,或在高质量数据上对其进行微调,以完成折叠多件衣物、组装箱体等复杂的多阶段任务。
采用预训练的视觉-语言模型(VLM)骨干网络,结合包含多种灵巧操作任务的多样化跨体数据集。通过添加一个独立的动作专家,适配机器人控制任务。该专家通过流匹配生成连续动作,从而实现精准且流畅的操作技能。随后,可通过提示词实现该模型的零样本控制,或在高质量数据上对其进行微调,以完成折叠多件衣物、组装箱体等复杂的多阶段任务。
流程与框架
推理流程
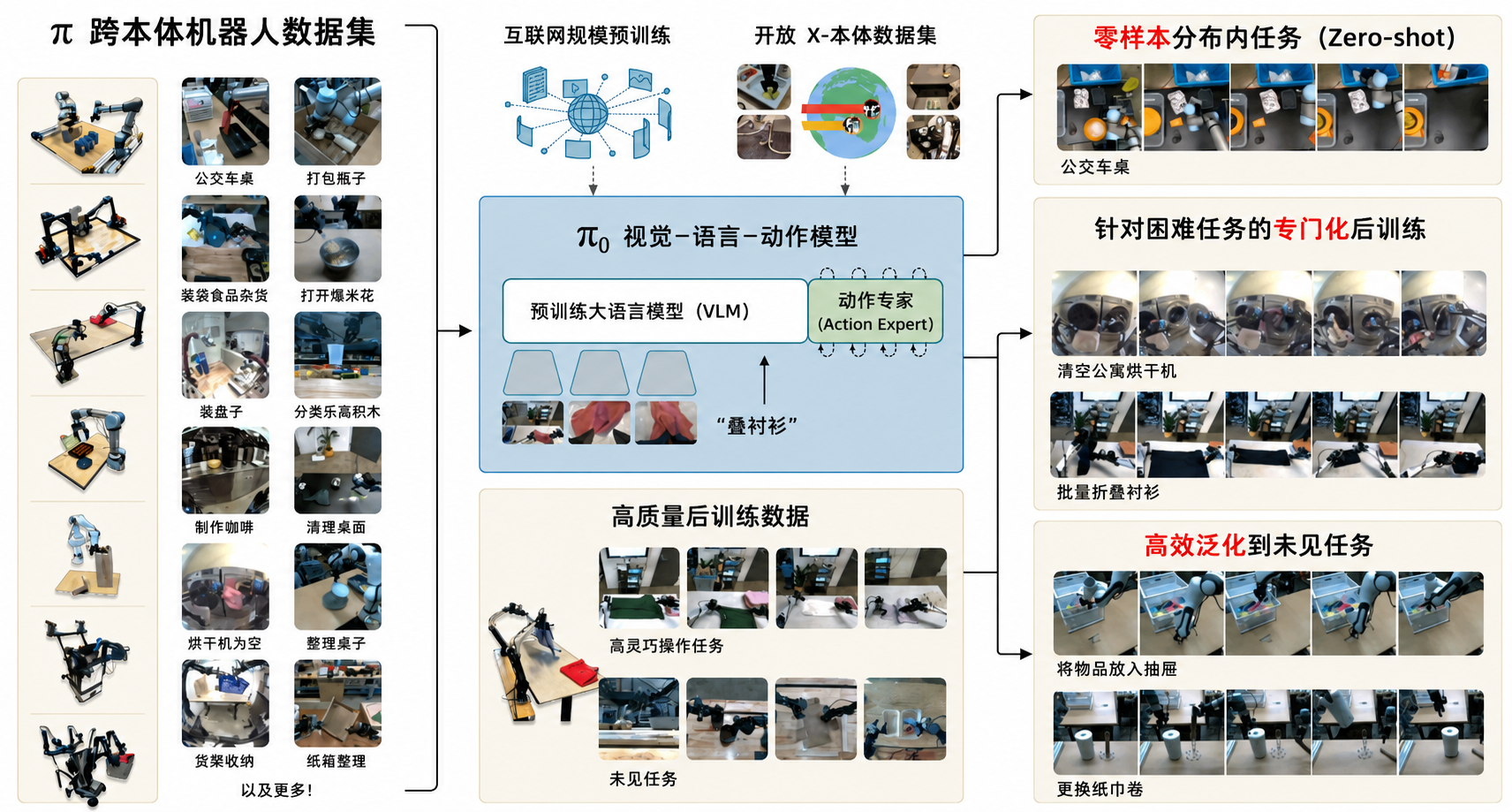
在推理时,系统首先输入视觉图像、语言指令、机器人当前本体状态以及一团初始随机噪声,并通过编码器将它们统一映射为相同维度的Token 。随后在单一Transformer架构内,视觉与语言Token路由给VLM提取语义上下文,状态与噪声Token路由给动作专家;动作专家通过自注意力机制实时共享VLM的上下文,进而对输入的噪声预测出去噪向量场,并经过连续积分去噪,最终生成包含未来50步连续物理动作的动作块交由机器人执行。
训练流程
在训练时,系统首先输入真实的视觉图像、语言指令、本体状态以及标准的未来动作块,并根据采样的时间步将标准动作与纯随机噪声混合生成“加噪动作”,随后所有输入被统一编码为相同维度的Token 。在单一Transformer架构内,Token进行分流:视觉与语言Token路由给VLM(VLM保持非冻结状态,直接参与微调),状态与加噪动作Token路由给动作专家 ;凭借“分块因果注意力掩码”机制,动作专家能单向、实时地共享VLM的语义上下文(同时严禁VLM向后查看物理数据,以防止灾难性遗忘),并借此对加噪动作预测出旨在恢复清晰动作的“去噪向量场” 。最终系统采用双目标联合驱动更新:系统对比预测方向与真实的去噪方向计算出流匹配损失,该损失的梯度会顺着注意力连接“倒流”回VLM,并结合VLM自身的语言交叉熵损失,联合反向传播以更新整个网络(包含VLM与动作专家)的权重。
分块因果注意力掩码(Blockwise Causal Attention Mask)
- 什么是“掩码” (Mask)?在 Transformer 网络中,所有的数据(Token)都在一起进行计算。而“注意力掩码”就像是给不同的 Token 戴上“眼罩”或安装“单向透视镜”,严格规定在计算时谁能看见谁,谁绝对不能看见谁。
- 数据被分成了哪三个“块” (Blocks)?在 模型中,输入序列被严格划分为了三个独立的区块:
区块 1(视觉与语言):包含多视角图像和文本指令(即 )。
区块 2(本体状态):机器人的当前物理状态(即 )。
区块 3(噪声动作):动作专家需要处理的、带有噪声的未来动作序列(即 )。 - 掩码的“游戏规则” (Blockwise Causal)这个名字里包含了它的两条核心规则: 块内双向 (Blockwise):在每一个区块内部,Token 之间可以互相“看”到彼此,实现完全的双向注意力(Full bidirectional attention)。比如,语言 Token 可以自由地参考图像 Token。
块间因果 (Causal):区块之间是严格的“单向不可逆”关系,任何一个区块中的 Token 都绝对不能去关注(attend to)排在它后面的未来区块。 - 为什么要这么设计?(三大神级优势)这种看似严格的隔离和单向通信机制,实际上同时解决了模型训练和推理中的三大痛点: 优势一:保护“大脑”,防止灾难性遗忘 (Distribution Shift):区块 1(视觉与语言)包含了 PaliGemma VLM 在预训练时就已经非常熟悉的模态,掩码机制严格禁止它们向后看到未来的区块(即禁止看到陌生的机器人状态和动作数据)。这极其巧妙地将 VLM 保护了起来,最小化了分布偏移,使得 VLM 在参与机器人控制训练时,依然能保留原本在互联网海量数据中学到的强大常识和推理能力,而不会因为接触了陌生的物理数据而“变笨”。
优势二:推理加速,实现毫秒级响应 (KV Caching):区块 2(机器人状态 )被单独列为一个区块,是因为在流匹配生成动作的多次积分循环中,机器人最初的物理状态是固定不变的。由于掩码禁止它看到排在最后的、不断变化的“噪声动作”区块,系统就可以在推理时将区块 2 对应的注意力键和值(Keys and Values)直接缓存(Cached)起来。这意味着在 10 步去噪循环中,系统不需要重复计算状态特征,大大提升了运算速度,确保了模型能以 50 Hz 的超高频率控制机器人。
优势三:赋予动作专家“上帝视角”:区块 3(噪声动作)排在序列的最后面,根据单向因果规则,它可以关注(attend to)前面所有的输入序列。这意味着动作专家在预测去噪向量场时,能够完美、实时地融合 VLM 提取的语义上下文以及机器人的本体感受,在拥有“全局全知视角”的前提下,做出最精准的物理动作判断。
总结一下:分块因果注意力掩码就像是公司里的信息单向汇报机制。VLM(高管)只负责看图文报告做决策,绝不碰底层代码(防止降智);动作专家(执行层)则能单向读取高管的所有决策精神和当前的设备状态,从而高效、精准地完成动作生成。
匹配流
- 它的本质是什么?
- 流匹配是一种先进的生成式 AI 技术(属于扩散模型的一种变体)。
- 在 模型中,它专门用于高精度地对连续的动作分布进行建模 。与传统大语言模型逐字生成离散 Token 不同,物理世界的机器人控制需要极其平滑、连续的指令,而这正是流匹配的强项 。
- 它的核心作用
- 高频连续控制:传统自回归模型很难做到又快又精细,而流匹配使模型能够以高达 50 Hz 的超高频率控制机器人,生成包含未来 50 步的连续“动作块”(Action Chunk),从而完成极其灵巧的任务(如快速叠衣服)。
- 训练阶段:
- 输入加噪:系统每次会从一个“偏向于极度混乱”的 Beta 分布中采样一个时间步 。根据这个时间步,系统故意将真实的完美动作指令与纯随机噪声按比例混合,生成一个“被污染的加噪动作” 。
- 预测向量场:动作专家接收这个加噪动作和当前的环境状态,其核心任务是预测出一个“去噪向量场” (Denoising Vector Field) 。通俗来说,就是预测出“把噪声剔除、恢复出正确动作轨迹的精确方向” 。
- 误差纠正:系统通过计算模型预测的去噪方向与真实的纯噪声到动作的差值之间的误差(流匹配损失,Flow Matching Loss),来反向更新网络权重 。
- 推理阶段:
- 起点:模型在没有标准答案的情况下,完全从一团纯粹的随机噪声开始 。
- 积分去噪:动作专家利用训练时学到的经验,顺着预测出的向量场方向,使用前向欧拉积分(Forward Euler Integration)法则进行连续 10 步的计算和去噪 。
- 最终输出:经过 10 步“雕刻”,这团毫无意义的随机噪声蜕变成为一个高度精确的连续动作序列(动作块),直接发送给机器人的电机执行 。
训练方案
采用了多阶段的训练过程。预训练阶段的目标是让模型接触各种各样的任务,从而获得广泛适用和通用的物理能力;而后训练阶段的目标是赋予模型熟练、流畅地执行所需下游任务的能力。
使用高级 VLM来进行语义推理
实验结果
评估基础模型
在完整的混合数据集上完成预训练后直接对模型进行评估,测试基础模型执行各种任务的能力 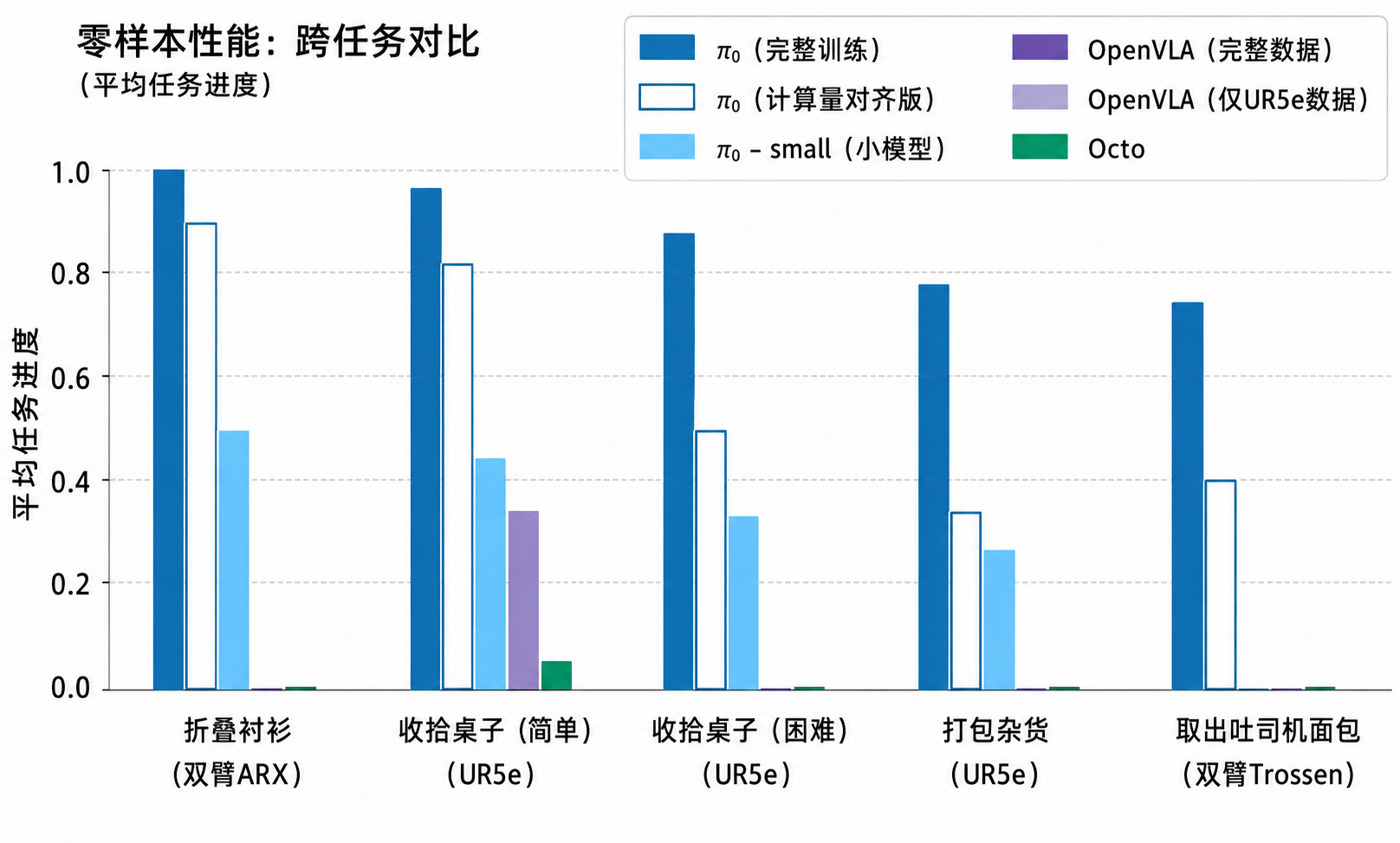
遵循语言指令
在一些评估领域中微调基础 模型以使其能够遵循细粒度的语言指令。将微调后的 模型与 -small 模型进行对比。衡量 VLM 预训练对模型遵循语言指令能力的提升幅度 -flat(以及 -small-flat):直接用总体任务描述来命令模型(例如“把杂货装袋”),不提供任何中间语言步骤指令 。
-human(以及 -small-human):由人类专家用户提供中间步骤指令(例如接下来拿哪个物体、放在哪里) 。
-HL:使用高级 VLM 策略自动生成并提供高层中间指令,该条件是完全自主的,无需人类参与 。 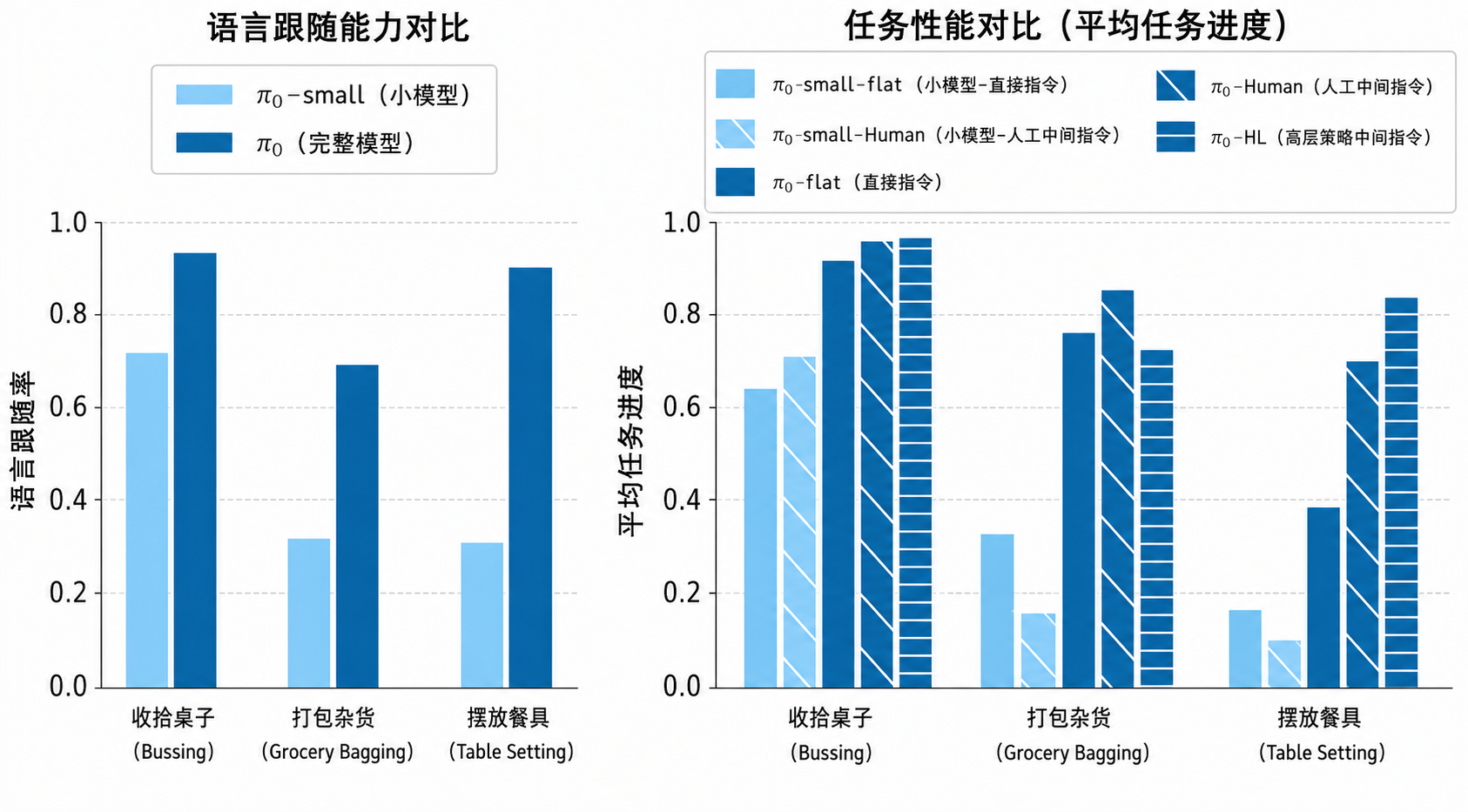
学习新的灵巧任务
在与预训练数据明显不同、需要全新行为的新任务上评估模型 将微调后的 与同样采用“预训练+微调”流程的 OpenVLA 和 Octo 的公开预训练检查点进行对比 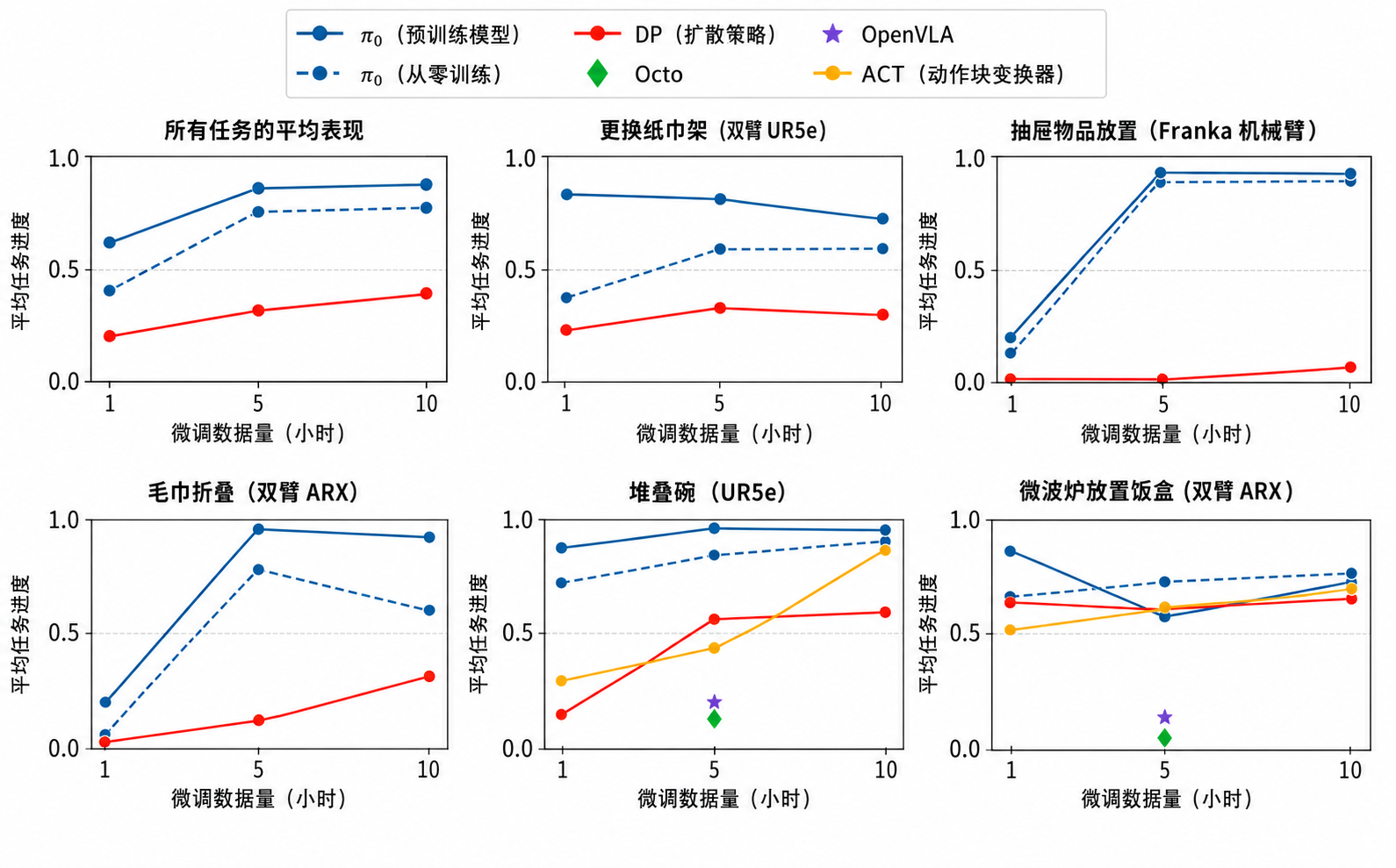
掌握复杂的长序列多阶段任务
通过结合微调和语言指令来攻克一系列极具挑战性的多阶段、长时段任务 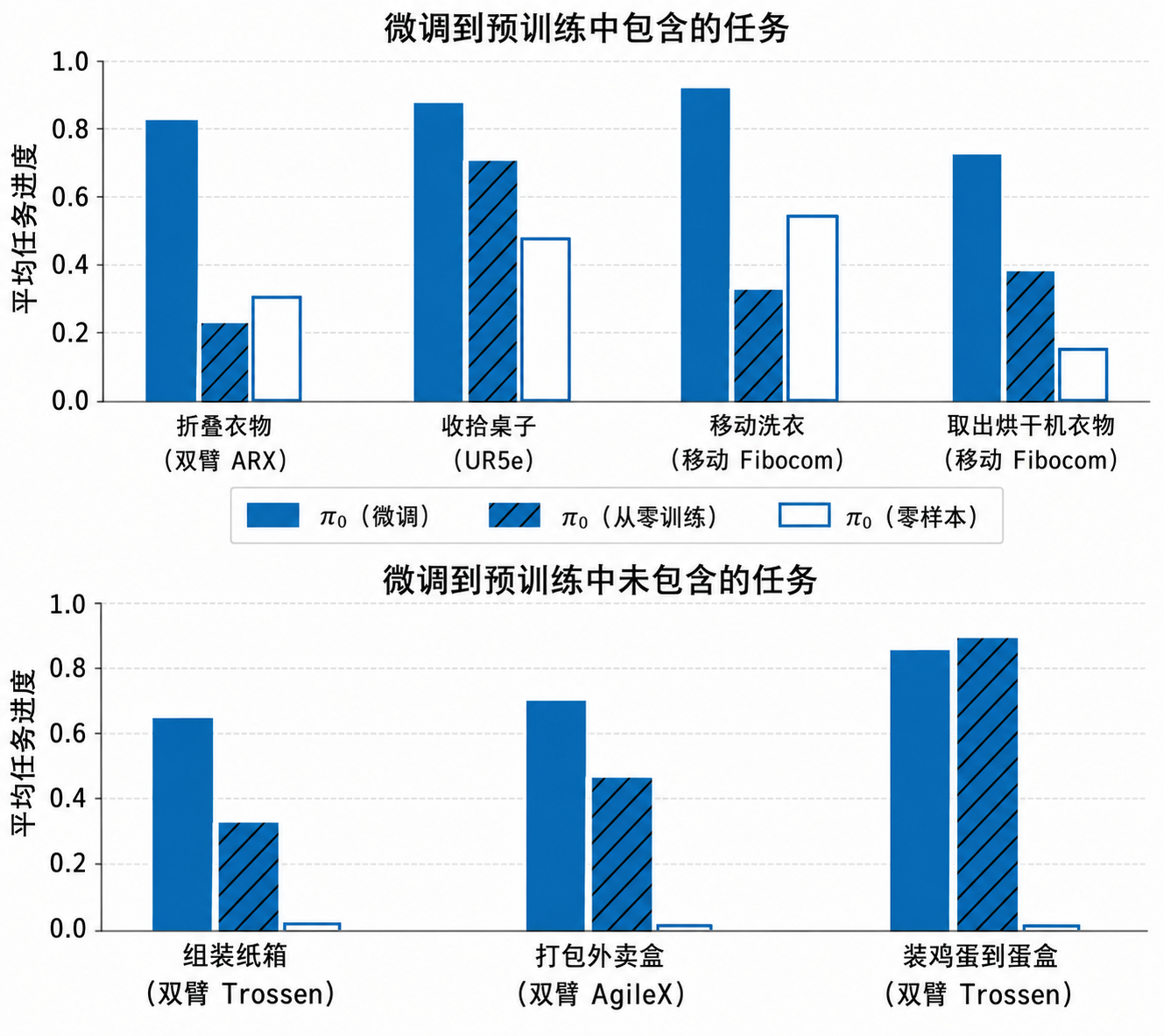
总结
提出了一个用于训练机器人基础模型()的框架 机器人基础模型可能会出现,大部分“知识”是在预训练阶段获得的,而后训练阶段的作用是告诉模型应如何利用这些知识来完成用户命令——预训练模型具有一定的零样本能力,但困难任务需要微调
局限性
目前尚不清楚如何预测需要多少以及何种类型的数据才能达到接近完美的性能
结合高度多样化的数据(特别是来自不同任务和不同机器人的数据)能带来多少正向迁移(positive transfer),仍有待观察 通用性是否能扩展还有待未来的工作去探索。
其他博客推荐
π0——用于通用机器人控制的VLA模型:一套框架控制7种机械臂
π0 and π0-FAST: Vision-Language-Action Models for General Robot Control