人工智能基础总结
该文档根据老师的总结ppt总结,如有知识点漏缺、错误等概不负责 多看ppt多看题,多问搜索引擎
人工智能基础总结

人工智能概述(选择题)
图灵测试
图灵测试用人类的表现来衡量假设的智能机器的表现,是评价智能行为的最好且唯一的标准。

给出了一个客观的智能概念,也就是根据对一系列特定问题的反应来决定是否是智能体的行为 通过使询问者只关注回答问题的内容,消除了有利于生物体的偏置
研究方法
符号主义:又称为逻辑主义、心理学派或计算机学派,是基于物理符号系统假设和有限合理性原理的人工智能学派 连接主义:又称为仿生学派或生理学派,是基于神经网络和网络间的连接机制与学习算法的人工智能学派 行为主义:又称为进化主义或控制论学派,是基于控制论和“动作一感知”控制系统的人工智能学派
知识表示


谓词逻辑与产生式表示法
函数符号与谓词符号
高扬是计算机系的一名学生,但他不爱编程序。 • 解:定义谓词如下: • Computer(x): x是计算机系的学生 • Like(x,y): x喜欢y • Computer(gaoyang)$\wedge $¬like(gaoyang, programing)
产生式表示法
通常用于表示具有因果关系的知识 基本形式:P→Q 或 IF P THEN Q P是前提,用于指出该产生式是否可用的条件; Q是一组结论或操作,用于指出当前提P所指出的条件被满足时,应该得出的结论或应该执行的操作。
产生式与谓词逻辑中蕴涵式的区别
产生式的基本形式和谓词逻辑中的蕴含式形式相同。但它们又有一定的区别
1、蕴含式只能表示精确知识。 2、产生式不仅可以表示精确知识也可以表示不精确知识。这是因为在产生式表示知识的系统中,事实与一条规则的前提条件的匹配可以是不精确的
语义网络
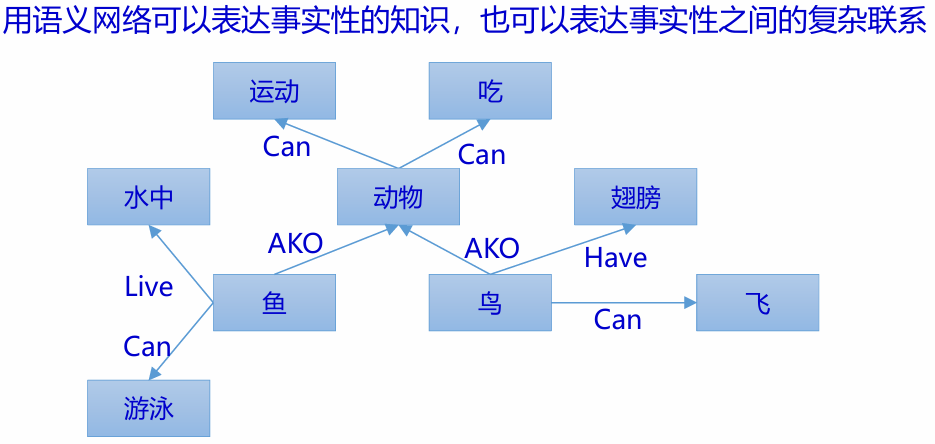
语义网络是一种通过概念及其语义联系(或语义关系)来表示知识的有向图,结点和弧必须带有标注 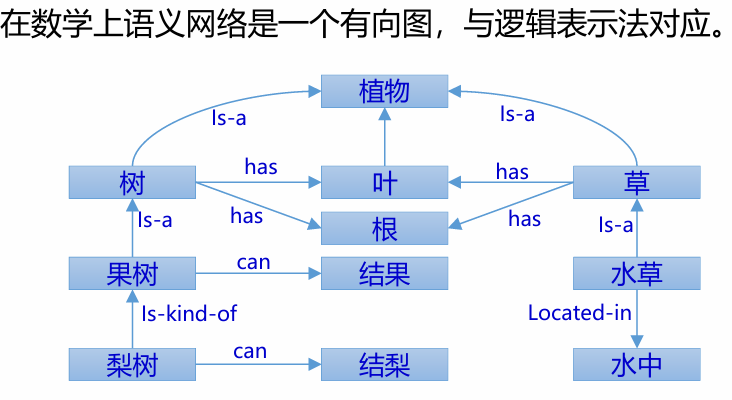
有向图的各结点用来表示各种事物、概念、情况、属性、状态、事件和动作等 结点上的标注用来区分各结点所表示的不同对象,每个各结点可以带有多个属性,以表征其所代表的对象的特性 结点还可以是一个语义子网络
弧是有方向的、有标注的,方向表示结点间的主次关系且方向不能随意调换。 标注用来表示各种语义联系,指明它所连接的结点间的某种语义关系。
从结构上来看,语义网络由一些最基本的语义单元组成。 最基本的语义单元被称为语义基元,可用如下三元组来表示为:(结点1,弧,结点2)
知识图谱
由有向图(directed graph)构成 被用来描述现实世界中实体及实体之间的关系 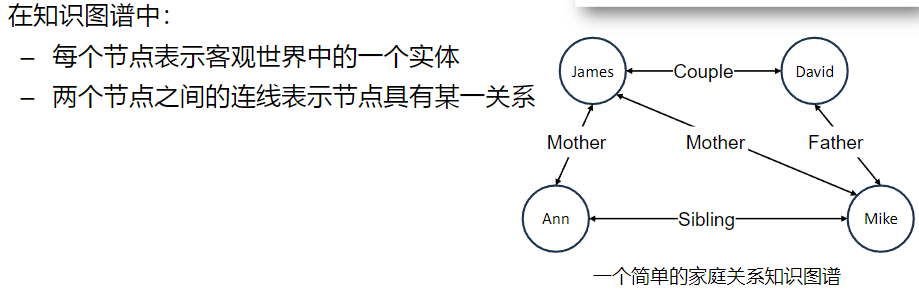

确定性推理
分类

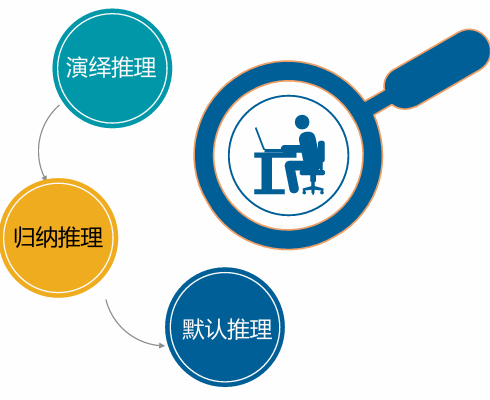
归纳推理
 按照推理所使用的方法可分为枚举、类比、统计和差异归纳推理等
按照推理所使用的方法可分为枚举、类比、统计和差异归纳推理等
枚举归纳推理:在进行归纳时,如果已知某类事物的有限可数个具体事物都具有某种属性,则可推出该类事物都具有此种属性 类比归纳推理:在两个或两类事物有许多属性都相同或相似的基础上,推出它们在其他属性上也相同或相似的一种归纳推理。
演绎推理与归纳推理的区别
演绎推理:在已知领域内的一般性知识的前提下,通过演绎求解一个具体问题或者证明一个结论的正确性 所得出的结论实际上早已蕴含在一般性知识的前提中,演绎推理只不过是将已有事实揭露出来,因此它不能增殖新知识
归纳推理所推出的结论是没有包含在前提内容中的 这种由个别事物或现象推出一般性知识的过程,是增殖新知识的过程
其他推理
默认推理

(非)单调推理

(不)确定性推理


(非)启发式推理


推理的控制策略
推理的控制策略主要包括推理方向、搜索策略、冲突消解策略、求解策略及限制策略等
推理方向
正向推理(数据驱动推理、前向链推理、模式制导推理及前件推理):从初始状态出发,使用规则,到达目标状态。
逆向推理(目标驱动推理、逆向链推理、目标制导推理及后件推理):以某个假设目标为出发点的一种推理。
混合推理:已知的事实不充分。通过正向推理先把其运用条件不能完全匹配的知识都找出来,并把这些知识可导出的结论作为假设,然后分别对这些假设进行逆向推理。先正向再逆向、先逆向再正向
双向推理:正向推理与逆向推理同时进行,且在推理过程中的某一步骤上“碰头”的一种推理。正向推理所得的中间结论恰好是逆向推理此时要求的证据
其他

自然演绎推理
自然演绎推理:从一组已知为真的事实出发,直接运用经典逻辑中的推理规则推出结论的过程称为自然演绎推理
自然演绎推理最基本的推理规则是三段论推理,包括:
两类错误: 肯定后件的错误:当P→Q为真时,希望通过肯定后件Q为真来推出前件P为真,这是不允许的 否定前件的错误:当P→Q为真时,希望通过否定前件P为假来推出后件Q为假,这也是不允许的
优点:定理证明过程自然,易于理解,并且有丰富的推理规则可用 缺点:容易产生知识爆炸,推理过程中得到的中间结论一般按指数规律递增,对于复杂问题的推理不利,甚至难以实现
例题



归结演绎推理
归结演绎推理是一种基于鲁宾逊(Robinson)归结原理的机器推理技术 鲁宾逊归结原理亦称为消解原理,是鲁宾逊于1965年在海伯伦(Herbrand)理论的基础上提出的一种基于逻辑的“反证法”
定理证明的实质,就是要对前提P和结论Q,证明P→Q永真。 要证明P→Q永真,就是要证明P→Q在任何一个非空的个体域上都是永真的。这将是非常困难的,甚至是不可实现的。

置换与合一
置换
定义
置换可简单的理解为是在一个谓词公式中用置换项去替换变量 
性质
置换乘法


合一
合一可理解为是寻找项对变量的置换,使两个谓词公式一致 
最一般合一(MGU, Most General Unifier)
设 σ 是公式集 F 的一个合一,如果对 F 的任一个合一 θ 都存在一个置换 λ,使得 θ = σ ° λ,则称 σ 是一个最一般合一(MGU)。 一个公式集的最一般合一是唯一的
差异集
表达式的非空集合W的差异集(difference set)是按下述方法得出的子表达式的集合: (1)在W的所有表达式中找出对应符号不全相同的第一个符号(自左算起)。 (2)在W的每个表达式中,提取出占有该符号位置的子表达式。这些子表达式的集合便是W的差异集D

计算MGU


鲁滨逊归结原理
子句与子句集
原子谓词公式及其否定统称为文字 例如,P(x)、Q(x)、﹁ P(x)、 ﹁ Q(x)等都是文字
任何文字的析取式称为子句 P(x)∨Q(x),P(x,f(x))∨Q(x,g(x))都是子句
不含任何文字的子句称为空子句 由于空子句不含有任何文字,也就不能被任何解释所满足,因此空子句是永假的,不可满足的。 空子句一般被记为□或NIL
由子句或空子句所构成的集合称为子句集
两个关键问题
第一,子句集中的子句之间是合取关系 子句集中只要有一个子句为不可满足,则整个子句集就是不可满足的
第二,空子句是不可满足的 一个子句集中如果包含有空子句,则此子句集就一定是不可满足的。
基本思想
首先把欲证明问题的结论否定,并加入子句集,得到一个扩充的子句集S' 。 然后设法检验子句集S'是否含有空子句, – 若含有空子句,则表明S'是不可满足的; – 若不含有空子句,则继续使用归结法,在子句集中选择合适的子句进行归结,直至导出空子句或不能继续归结为止
鲁滨逊归结原理包括: – 命题逻辑归结原理 – 谓词逻辑归结原理
命题逻辑的归结(难点)
若P是原子谓词公式,则称P与﹁P为互补文字

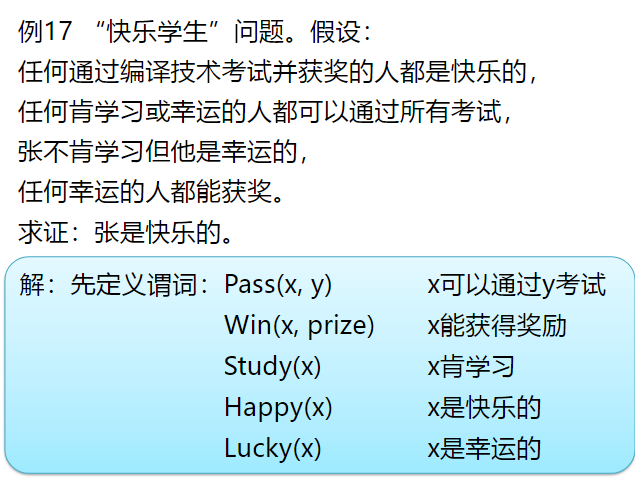
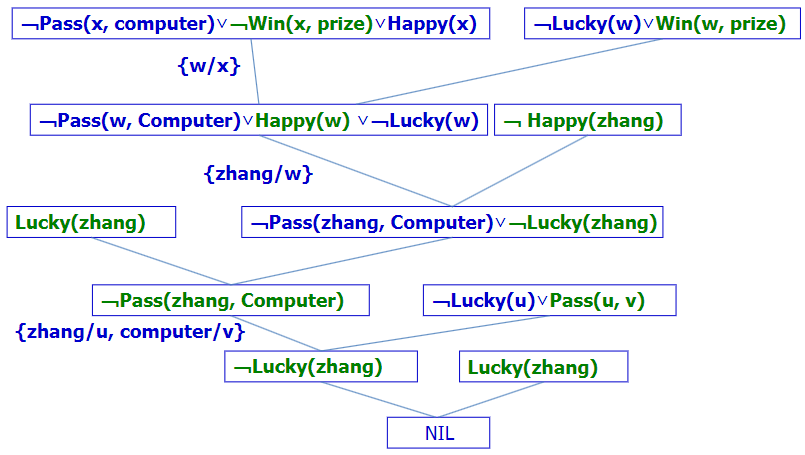
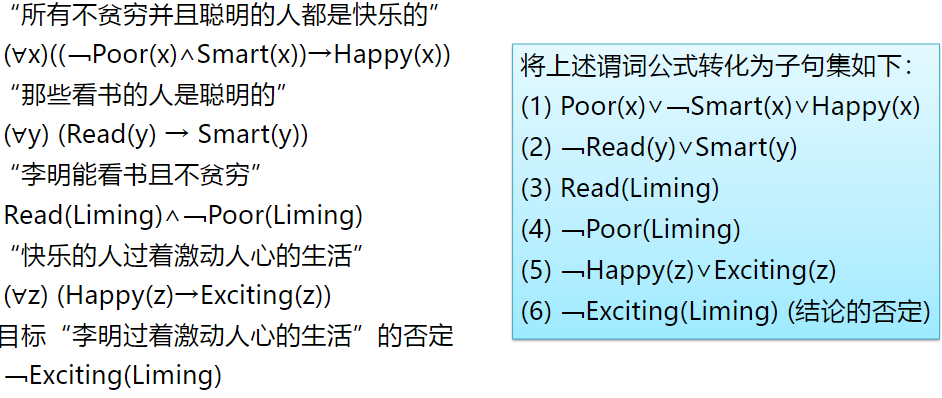
谓词逻辑的归结(难点)


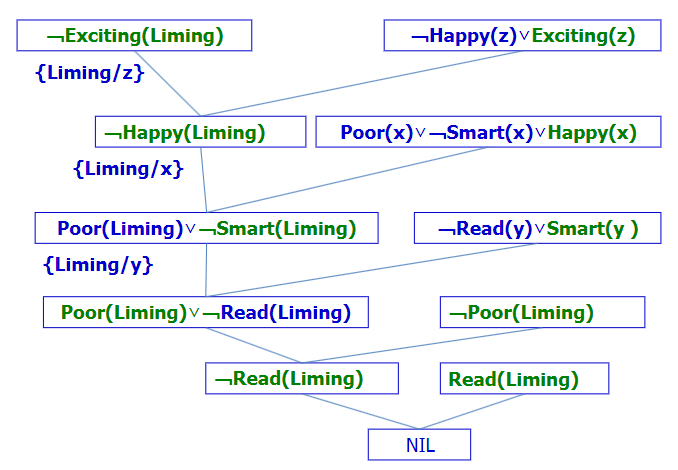





搜索
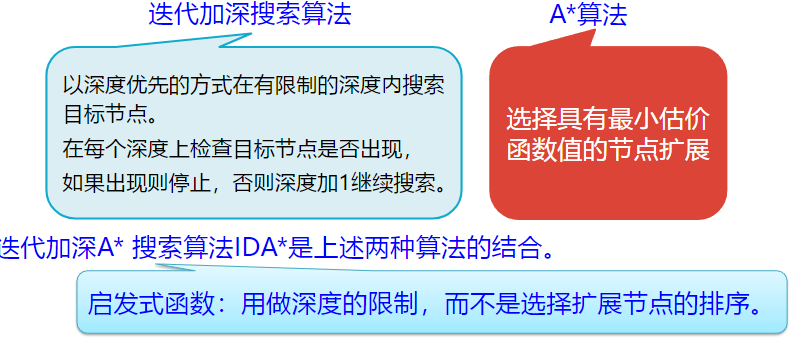
启发式搜索
启发式搜索:启发式知识指导OPEN表排序的一般图搜索: – 全局排序——对OPEN表中的所有节点排序,使最有希望的节点排 在表首。如:• A算法, A*算法 – 局部排序——仅对新扩展出来的子节点排序,使这些新节点中最有 希望者能优先取出考察和扩展。如:爬山法(对深度优先法的改进)
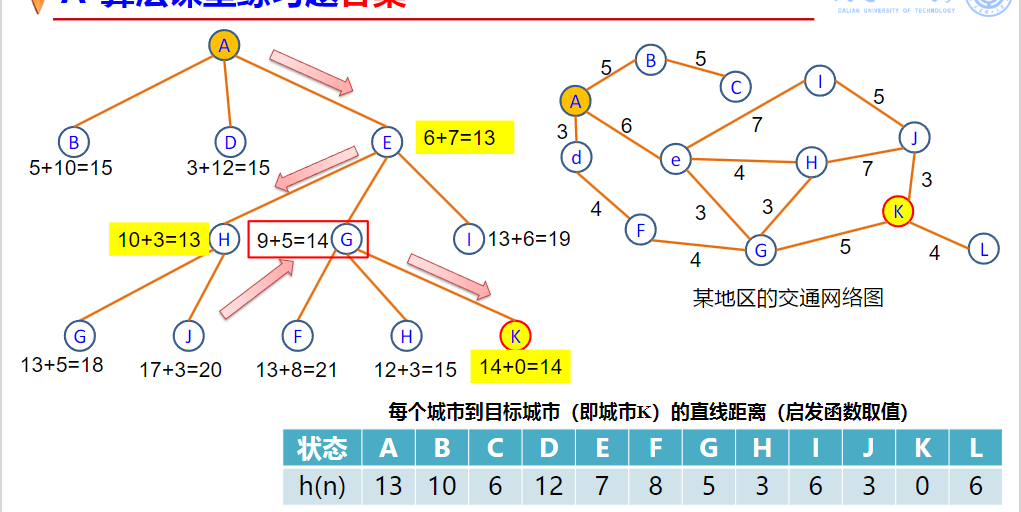
启发式搜索算法A
评价函数 f(n)=g(n)+h(n) h(n):从n到ng,估计的最小路径代价; h(n)值:依赖于启发式知识加以计算; h(n)称为启发式函数(掌握意义!) 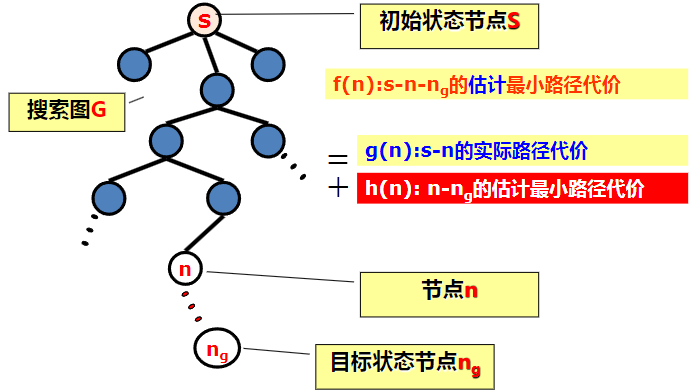

可采纳性
定义:在存在从初始状态节点到目标状态节点解答路径的情况下,若一个搜索法总能找到最短(代价最小)的解答路径,则称该状态空间中的搜索算法具有可采纳性,也叫最优性。 如:宽度优先的搜索算法是可采纳的,只是搜索效率不高
A算法的可采纳性——定义f*(n)=g*(n)+h*(n) – n:搜索图G中最短解答路径的节点; – f*(n):s经节点n到ng的最短解答路径的路径代价; – g*(n):该路径前段(从s到n)的路径代价; – h*(n):该路径后段(从n到ng)的路径代价 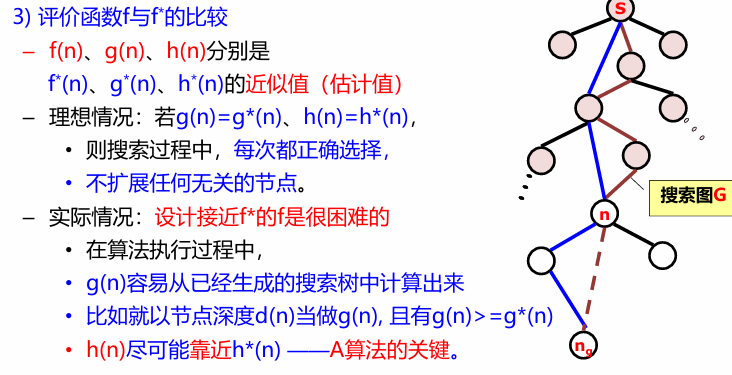
A*算法
A算法定义: – 1、在A算法中,规定h(n)≤h(n); – 2、经如此限制以后的A算法就是A*算法。
A*算法是可采纳的,即总能搜索到最短解答路径

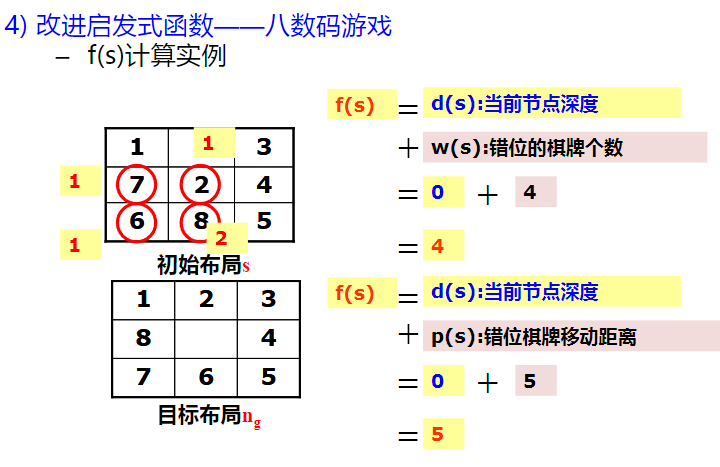

习题
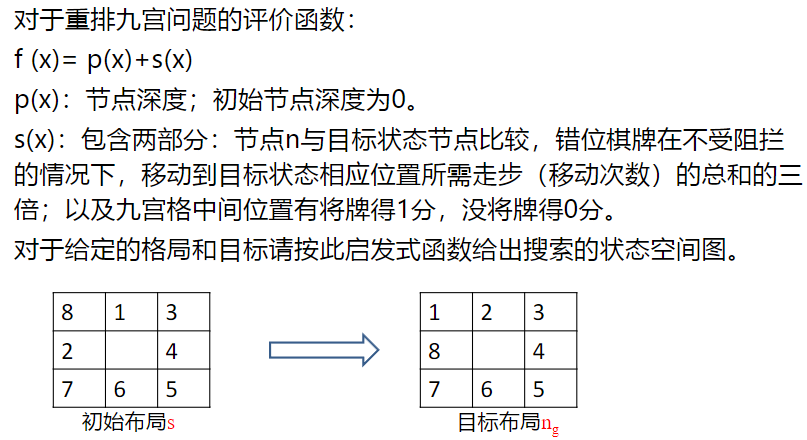
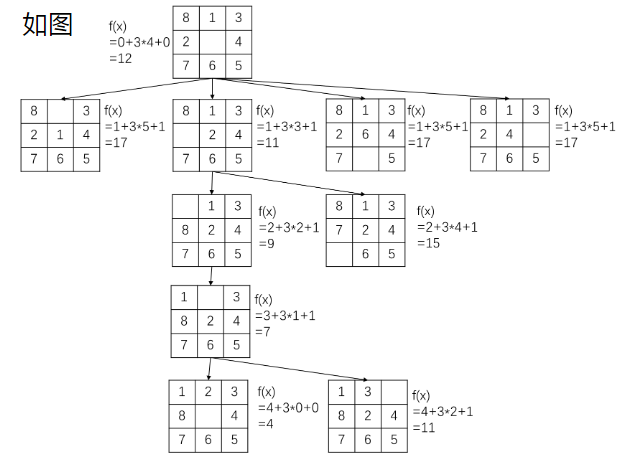
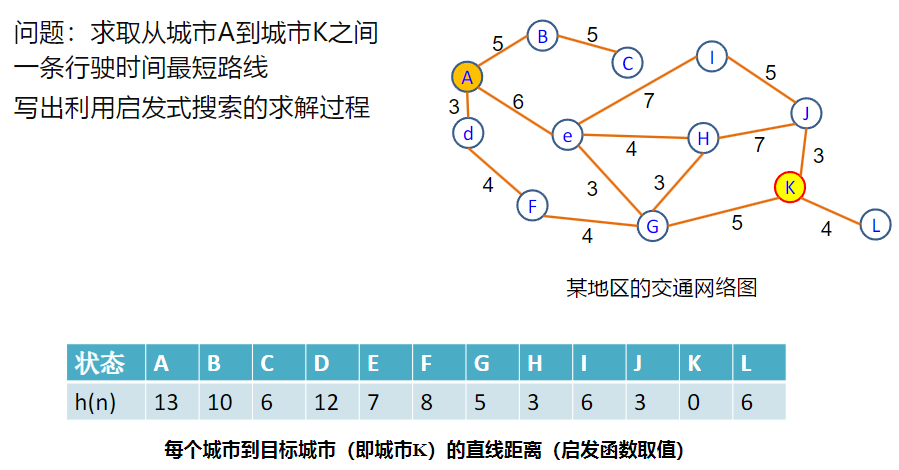
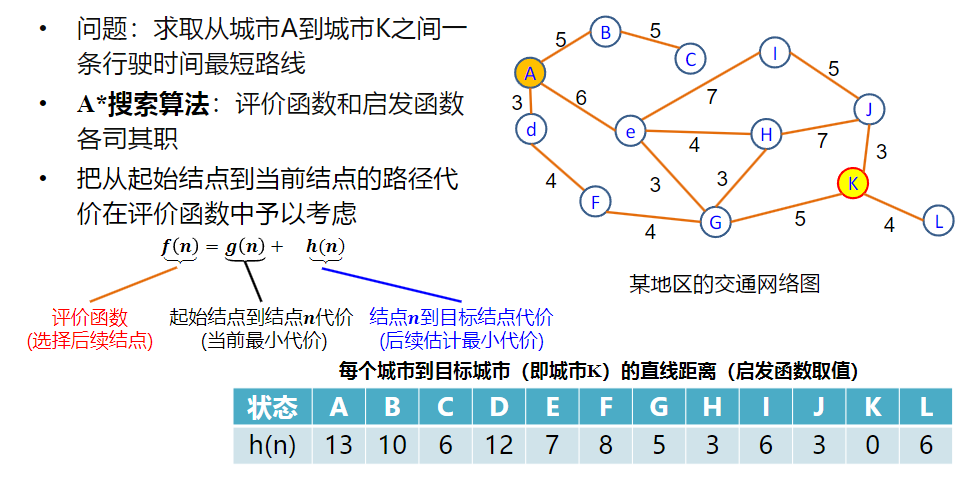
迭代加深A* 算法IDA*


爬山法与回溯策略
爬山法
 对于单一极值问题十分有效而又简便 对于具有多极值的问题无能为力——会错登上次高峰而失败:不能到达最高峰。 不存储历史记录:没有能力从错误或错误路径中恢复 局部贪心的最优算法
对于单一极值问题十分有效而又简便 对于具有多极值的问题无能为力——会错登上次高峰而失败:不能到达最高峰。 不存储历史记录:没有能力从错误或错误路径中恢复 局部贪心的最优算法
回溯策略
克服爬山法面临的困难:保存每次扩展出的子节点,并按h(n)值从小到大排列。 相当于爬山的过程中记住了途经的岔路口 – 路径搜索失败时回溯(后退),向另一路径方向搜索


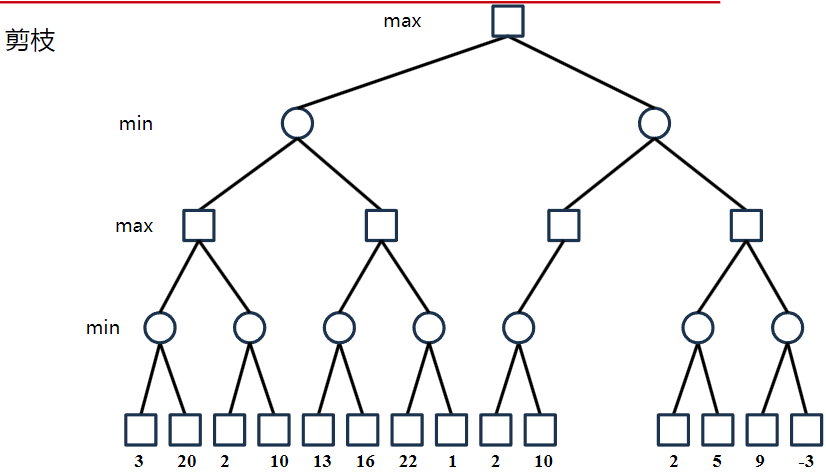
博弈
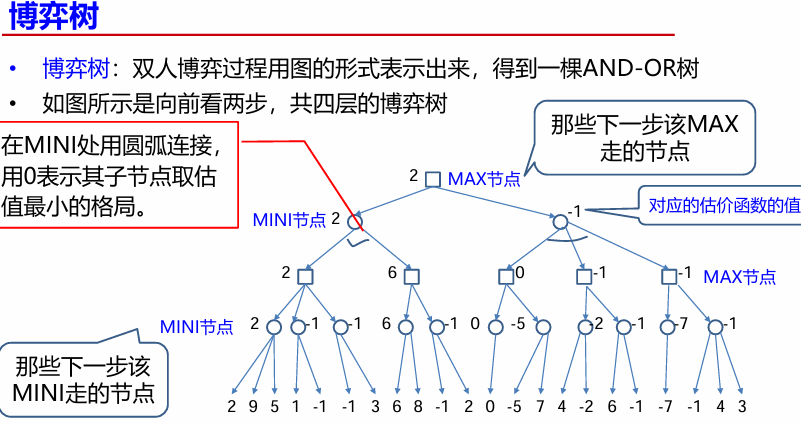
博弈树

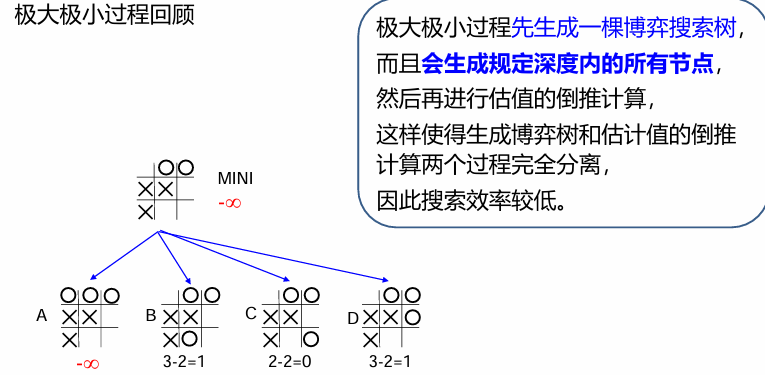
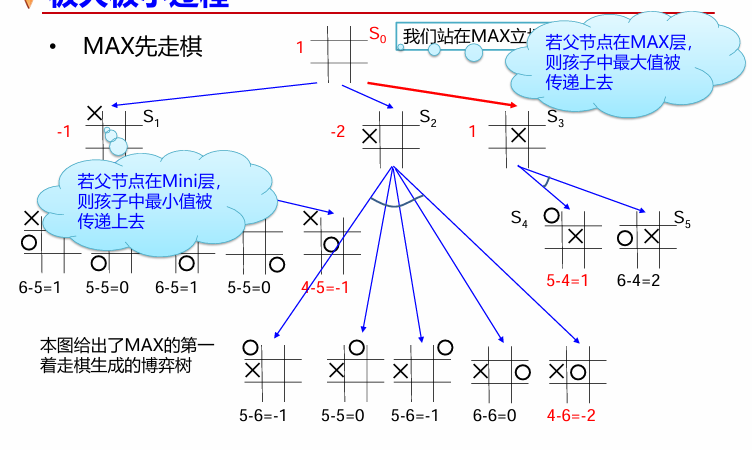
极大极小过程
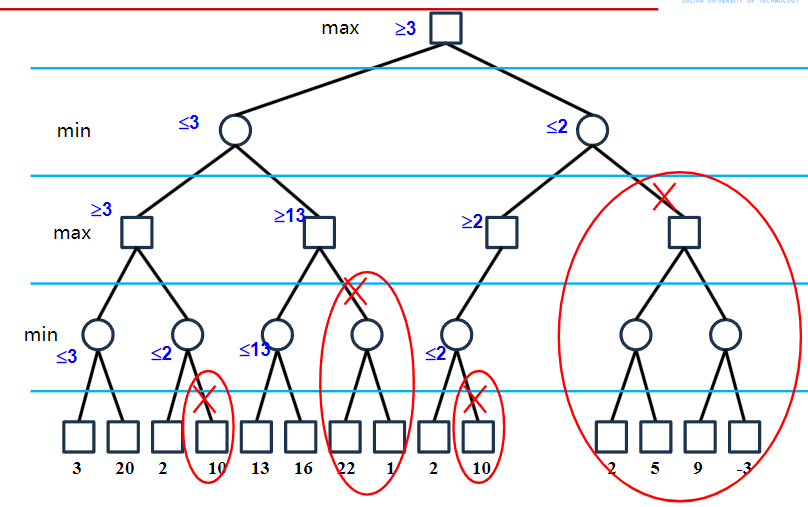
α-β过程


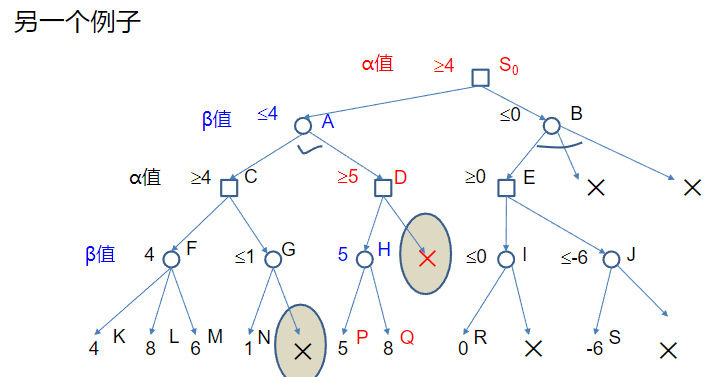
 在搜索深度相同的条件下: – 采用α-β过程所获得的走步总跟简单的MaxMini过程的结果是相同的 – 区别:α-β过程通常只用少得多的搜索便可以找到一个理想的走步。
在搜索深度相同的条件下: – 采用α-β过程所获得的走步总跟简单的MaxMini过程的结果是相同的 – 区别:α-β过程通常只用少得多的搜索便可以找到一个理想的走步。
深度学习

感知器
单层感知机

感知器学习算法
基于迭代的思想,通常是采用误差校正学习规则的学习算法。 可以将偏差作为神经元突触权值向量的第一个分量加到权值向量中 输入向量和权值向量可分别写成如下的形式:$X(n) = [ +1,x_1(n),x_2(n),...,x_m(n)]^T w(n)=[b(n),w_1(n),w_2(n),...,w_m(n)]^T$
第一步,设置变量和参量。 第二步,初始化 第三步,输入一组样本,并给它的期望输出 。 第四步,计算实际输出: 第五步,求出期望输出和实际输出求出差 

建立模型
激活函数
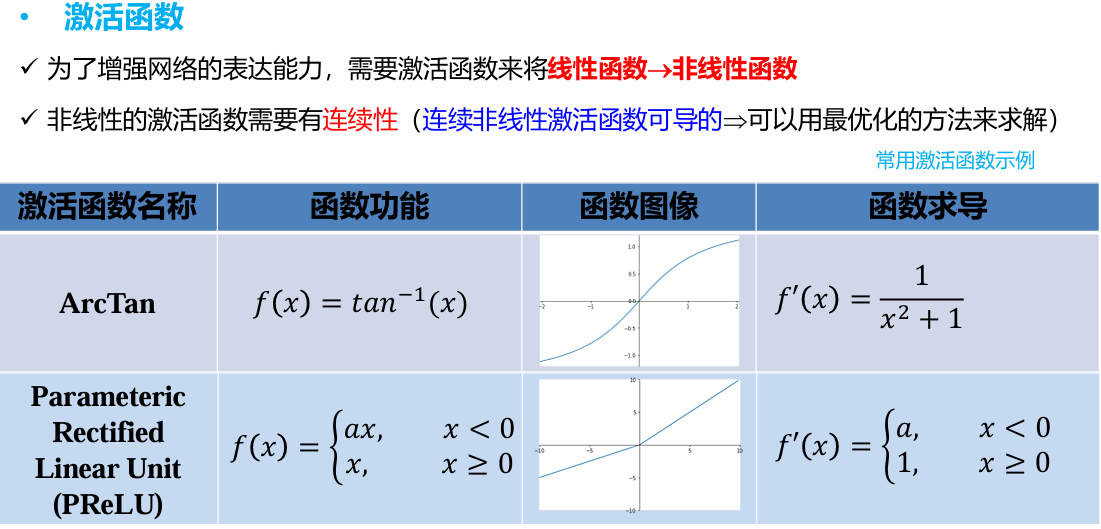
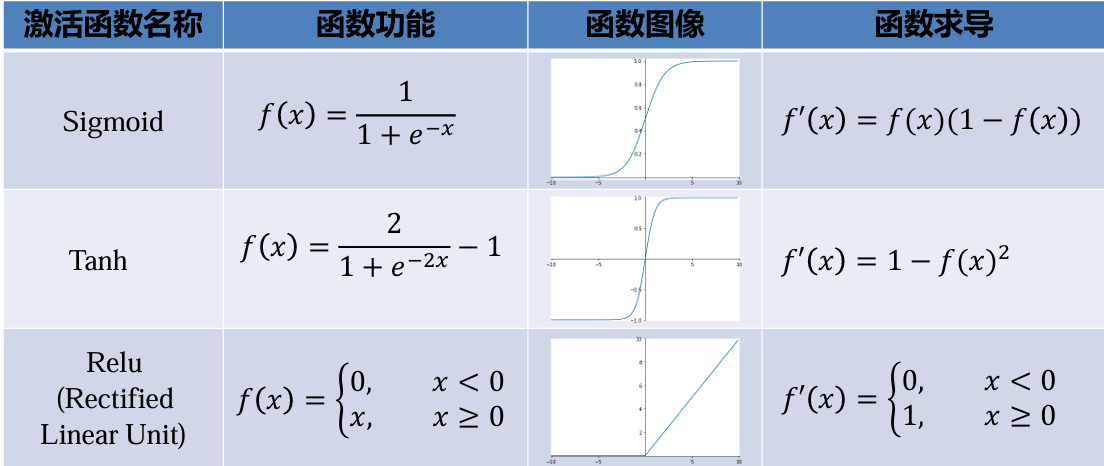 常用的只有Sigmoid、 Tanh、Relu,记住相应的范围就好(大概)
常用的只有Sigmoid、 Tanh、Relu,记住相应的范围就好(大概)
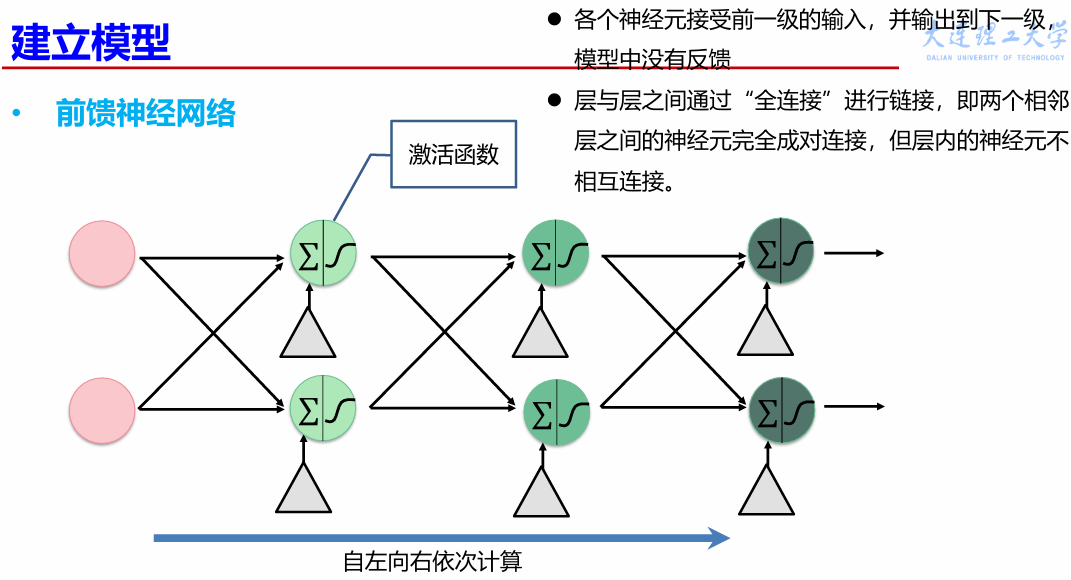
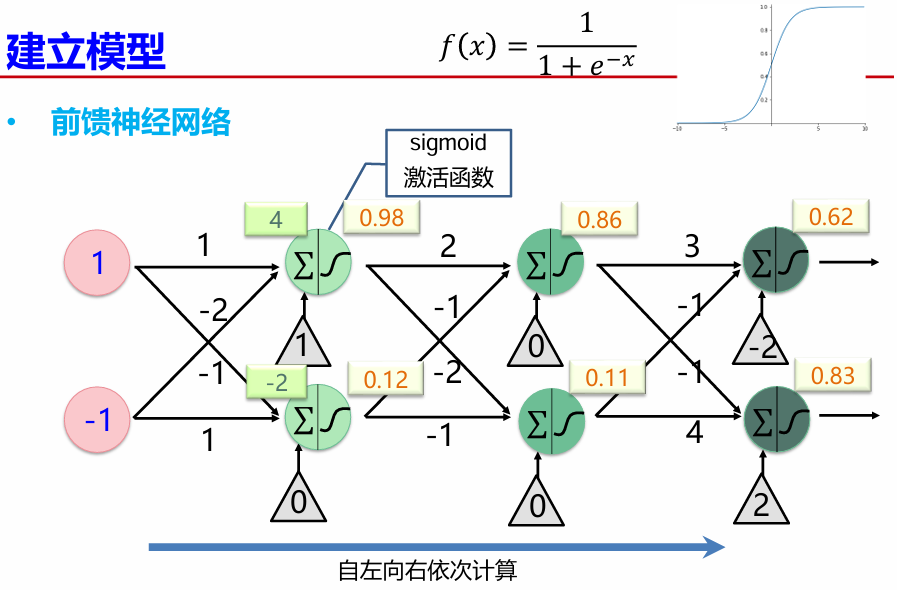
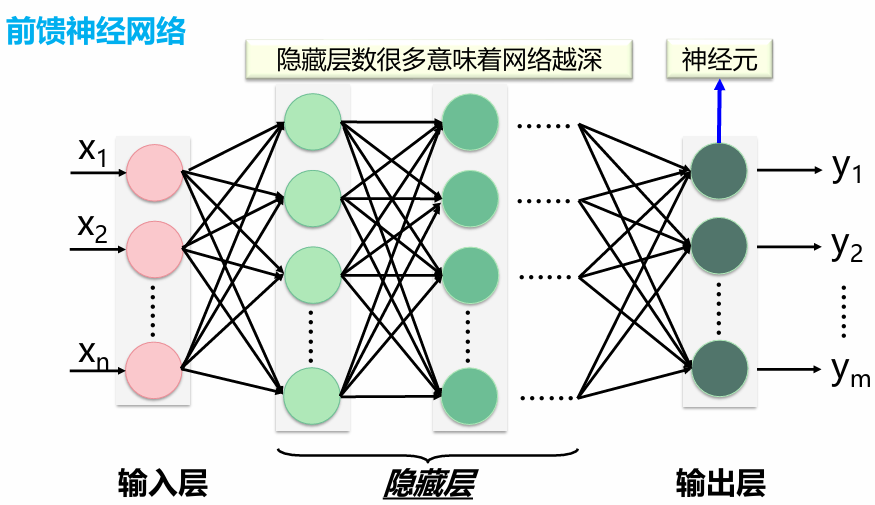
前馈神经网络
前馈神经网络(Feedforward Neural Network)是典型的深度学习模型。 具有以下特点: – 输入节点并无计算功能,只是为了表征输入矢量各元素值 – 每个神经元只与前一层的神经元相连;接收前一层的输出,并输出给下一层。采用一种单向多层结构;整个网络中无反馈,信号从输入层向输出层单向传播,可用一个有向无环图表示。 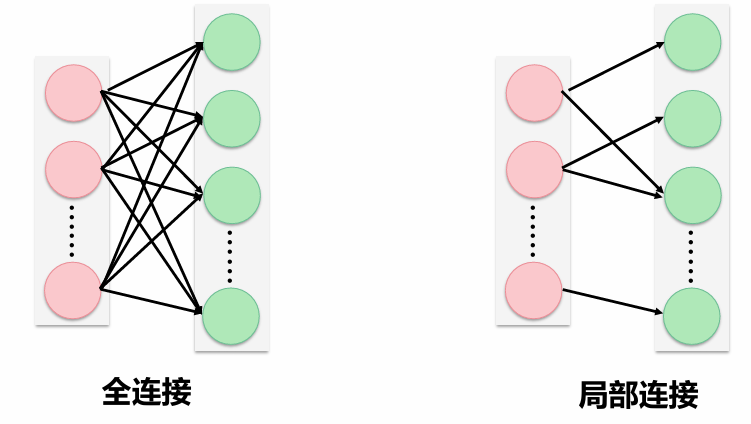
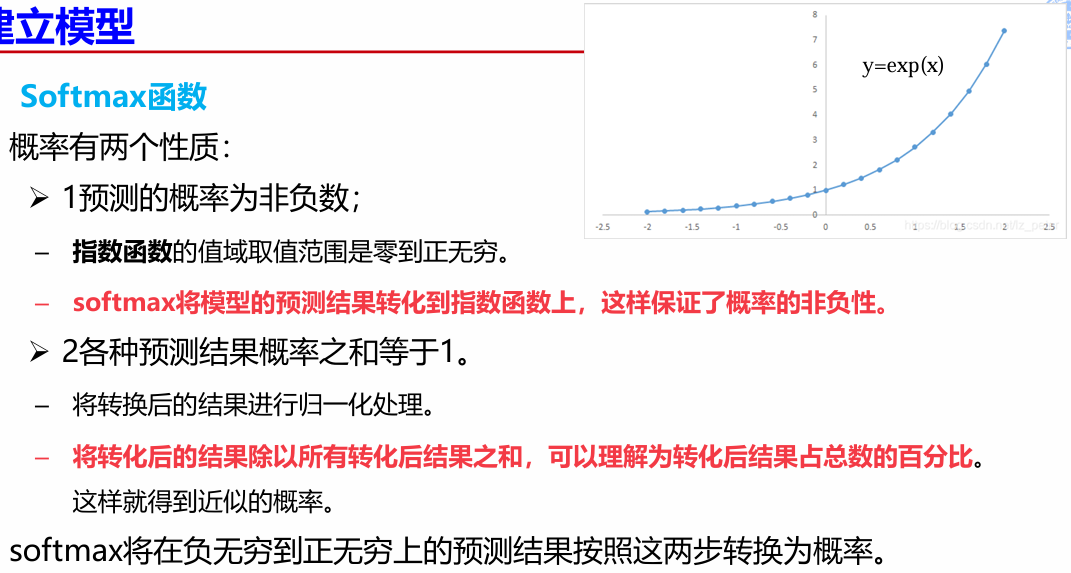
Softmax函数
输出层
常用softmax函数作为输出层激活函数:容易理解、便于计算 一般用于多分类问题 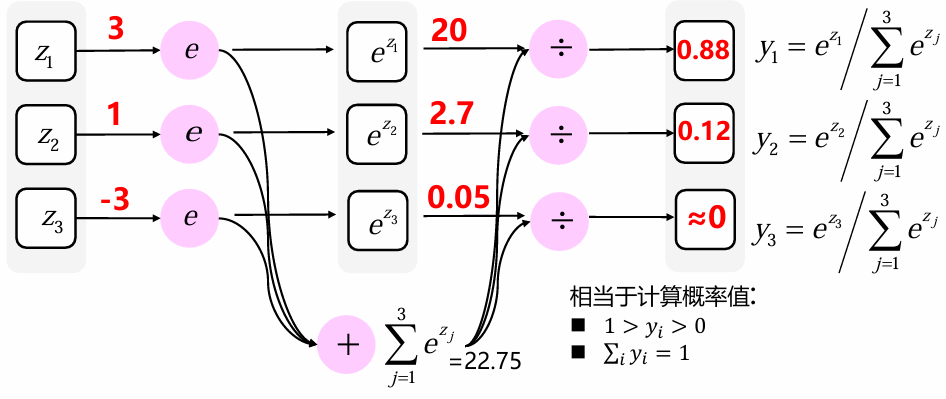
损失函数
损失函数(loss function)又称为代价函数(cost function),用来计算模型预测值与真实值之间的误差 常用损失函数:平方损失函数、交叉熵损失函数 好的参数使得所有训练数据的损失越小越好 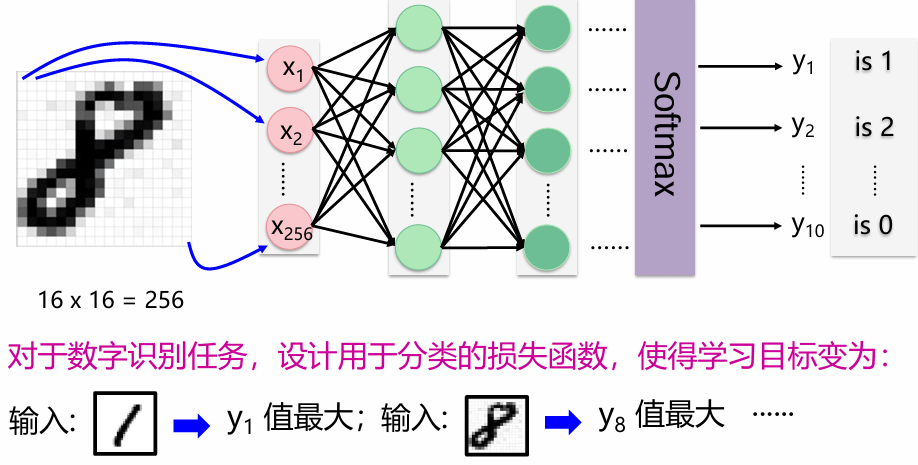
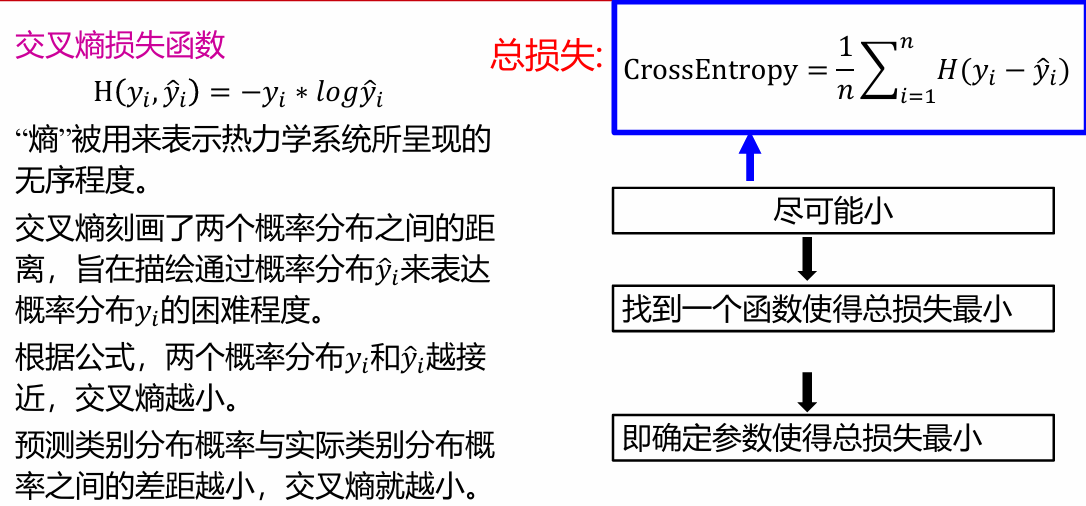
参数学习
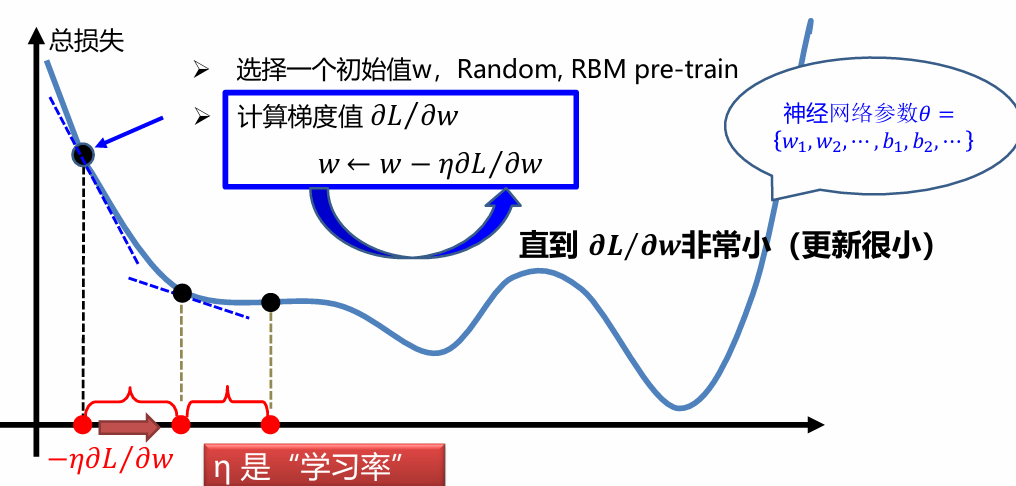
梯度下降法
梯度下降算法是一种使得损失函数最小化的方法。 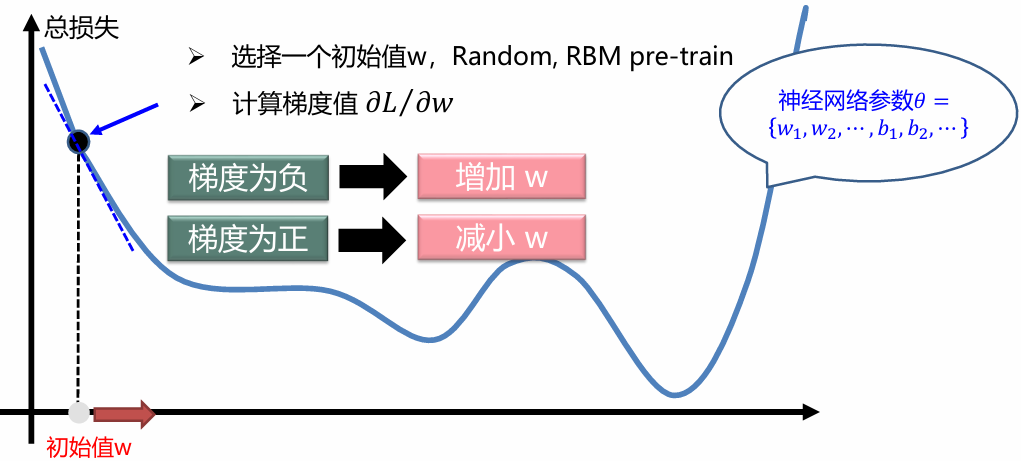
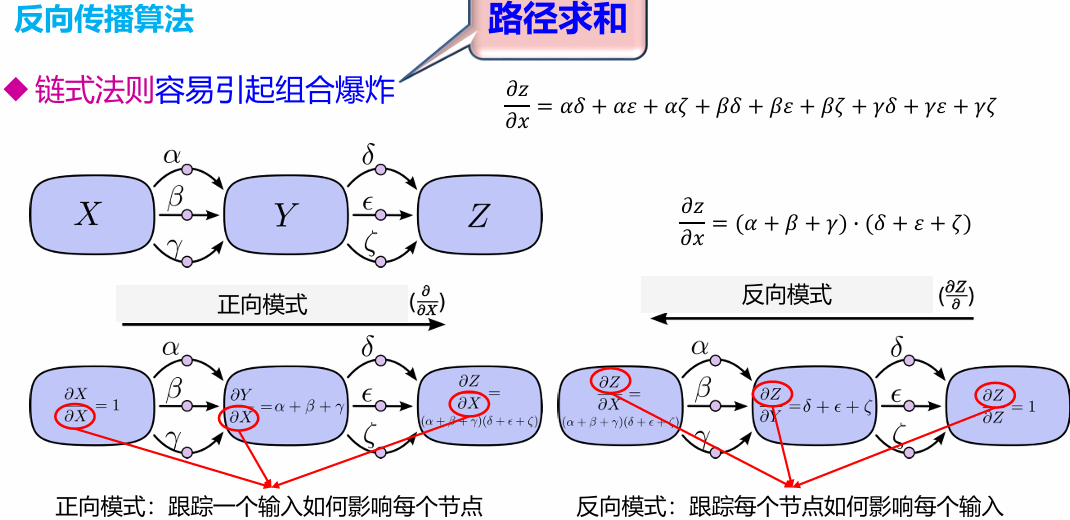
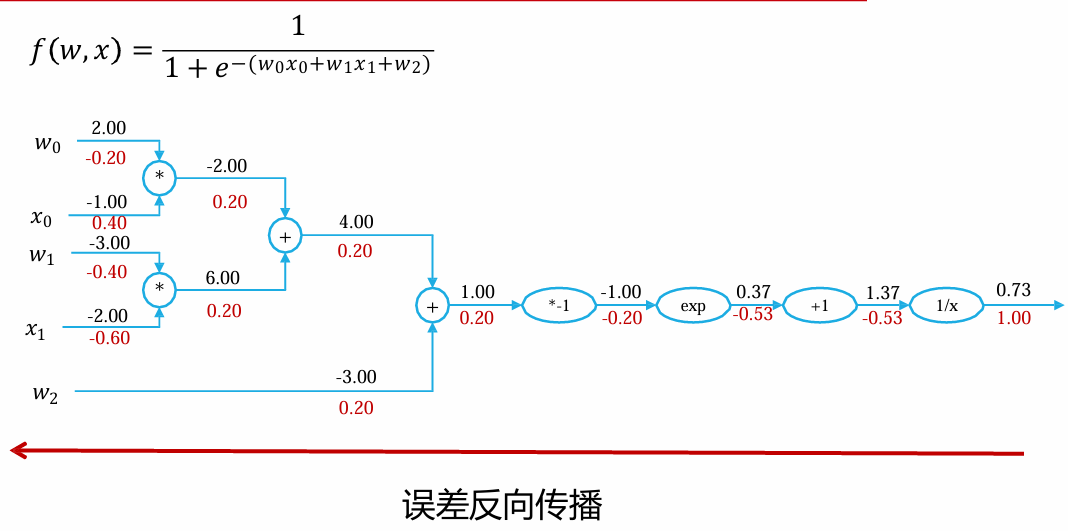
反向传播算法(BP算法)
BP算法是一种将输出层误差反向传播给隐藏层进行参数更新的方法 将误差从后向前传递,将误差分摊给各层所有单元,从而获得各层单元所产生的误差,进而依据这个误差来让各层单元负起各自责任、修正各单元参数。 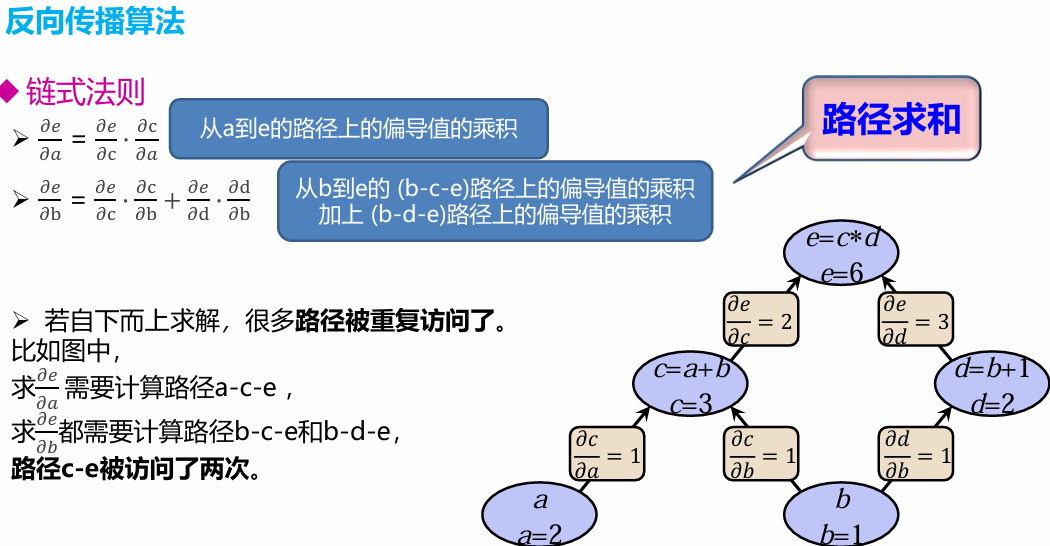
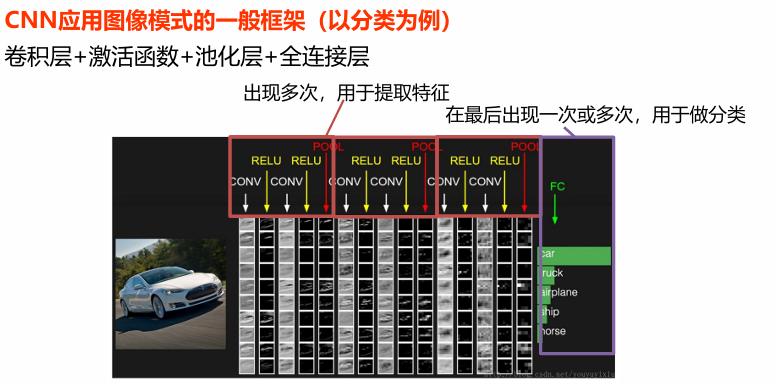
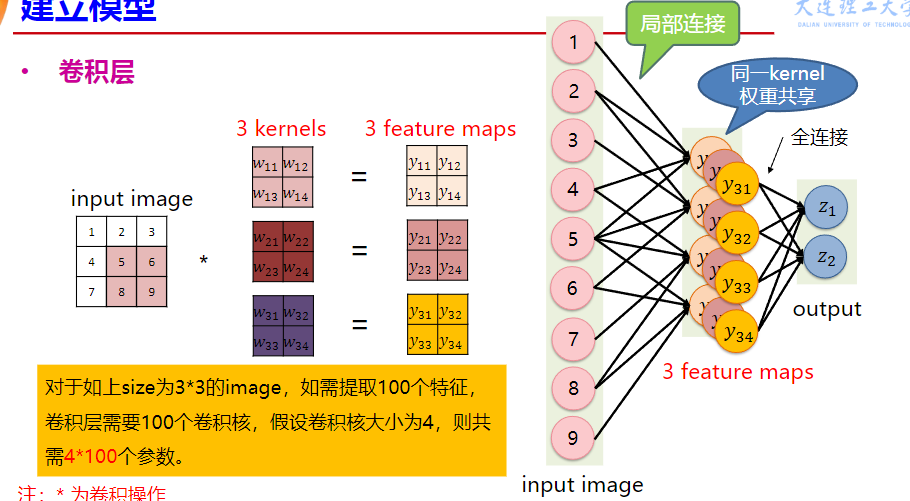
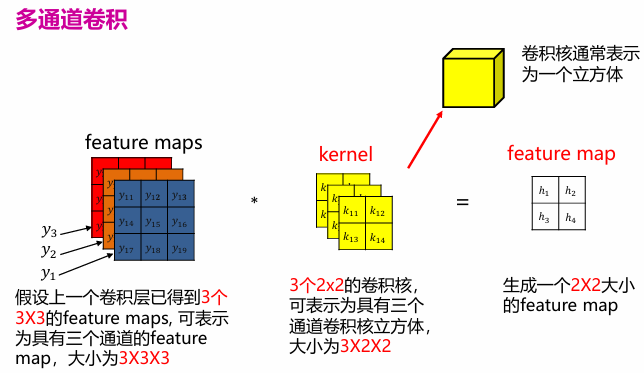
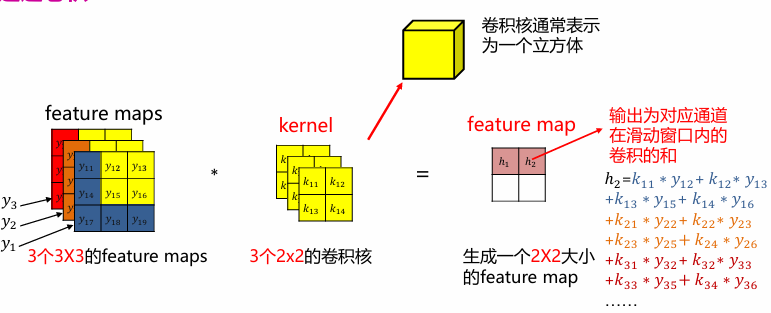
CNN


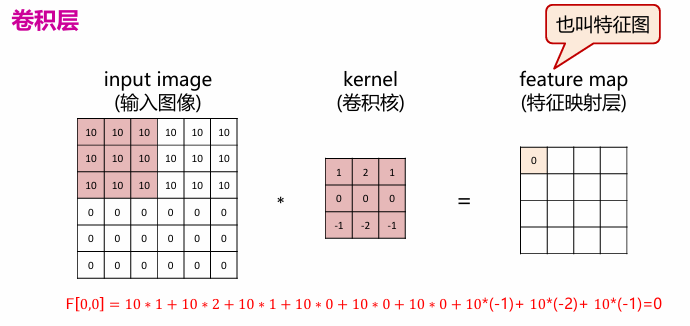
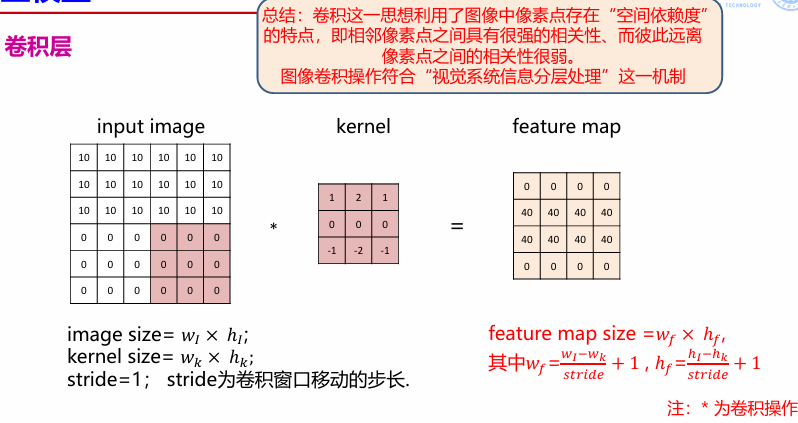
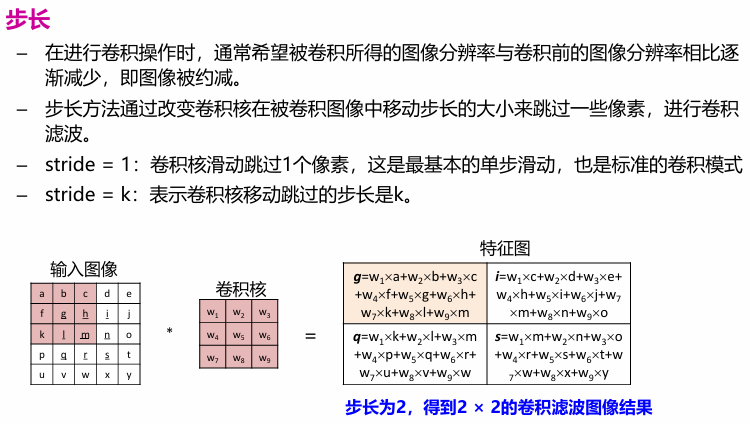
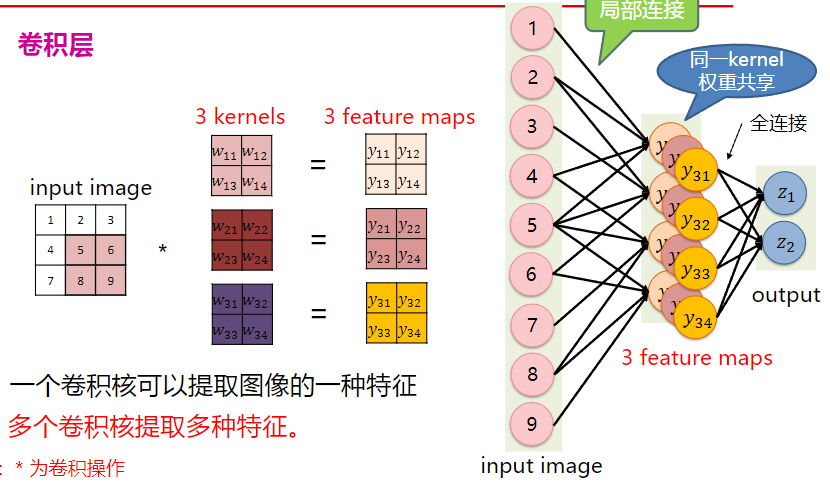
卷积
卷积用来提取图片特征 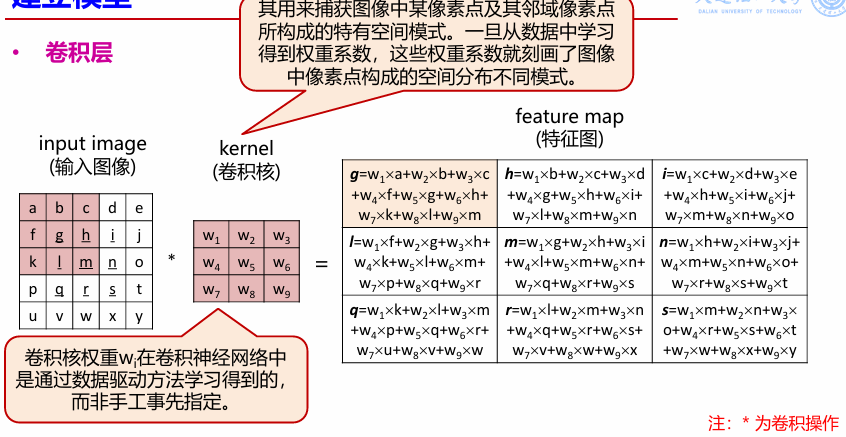

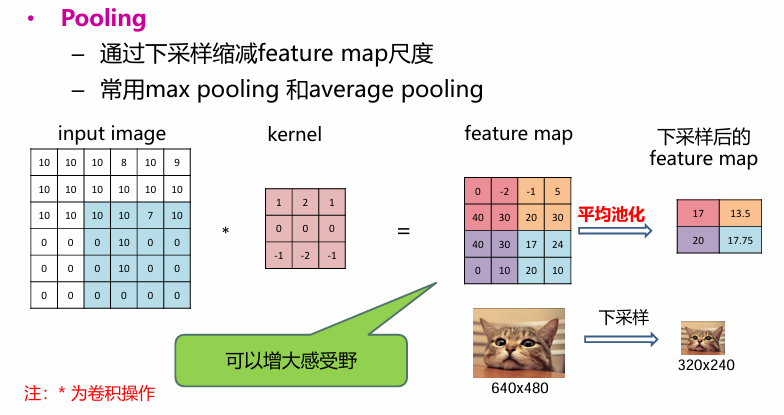
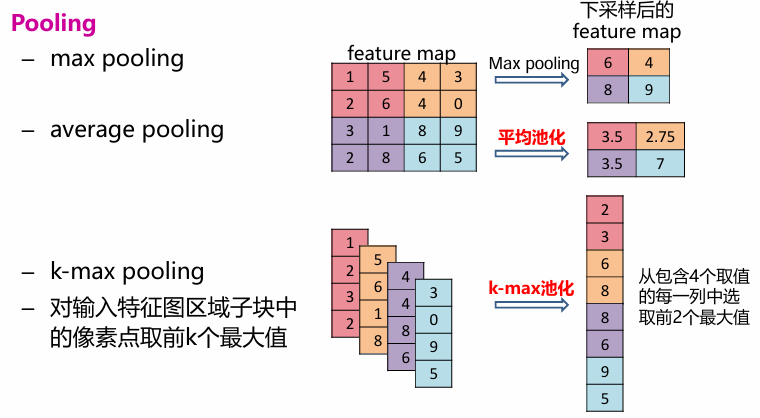
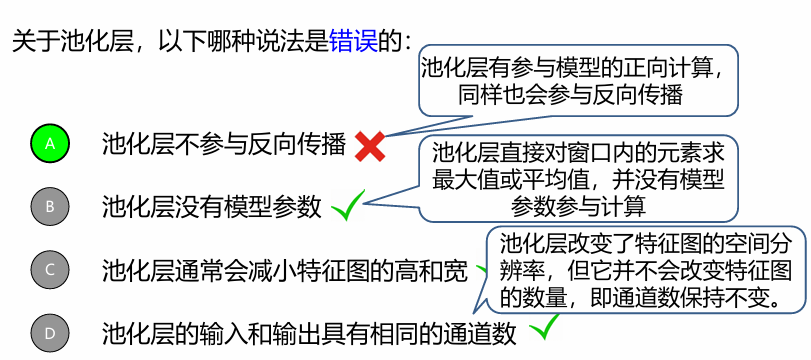
池化
- 下采样可以降维、去除冗余信息
- 实现非线性,一定程度上能防止过拟合的发生
- 可以实现特征不变性
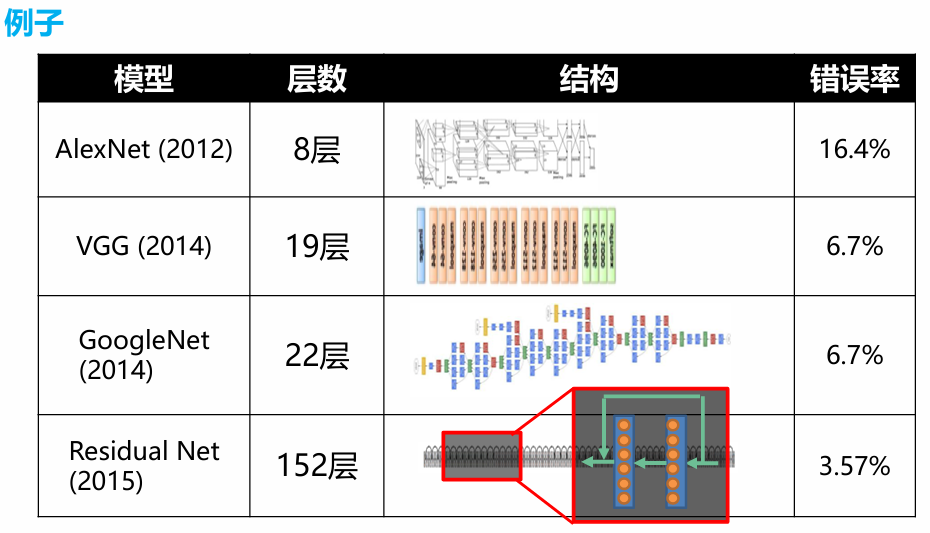
CNN发展史

习题






循环神经网络
变长输入:不同大小的图片、时长不一的视频、长短不同的句子、序列长度不同的对话 相互依赖:视频由连续的图片组成、词义取决于上下文、情感取决于上下文
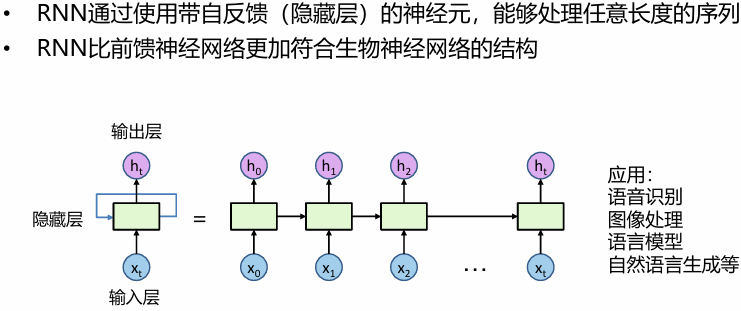
RNN
基本内容
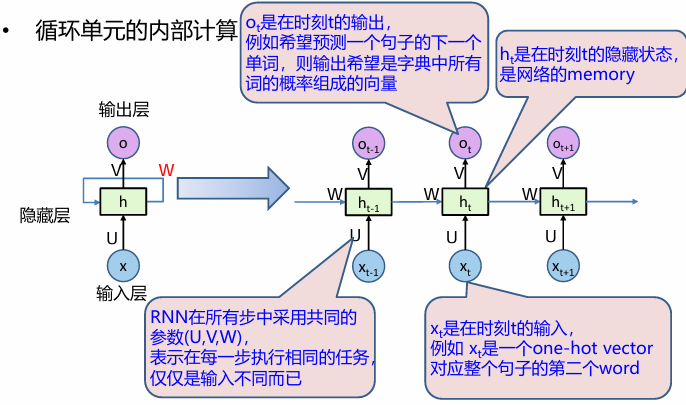
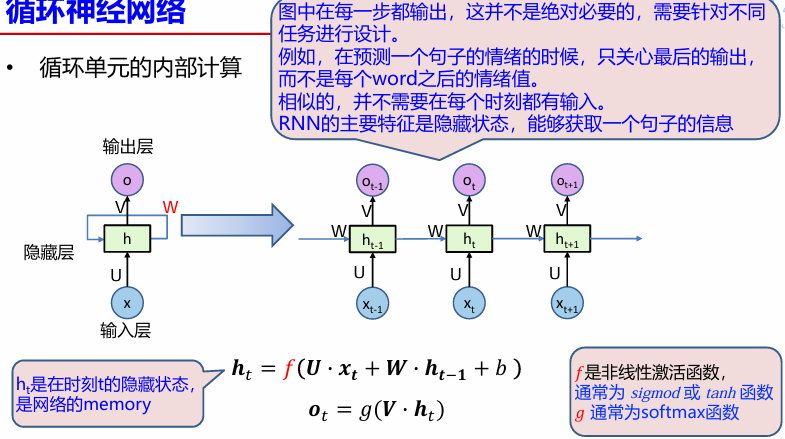
训练方式


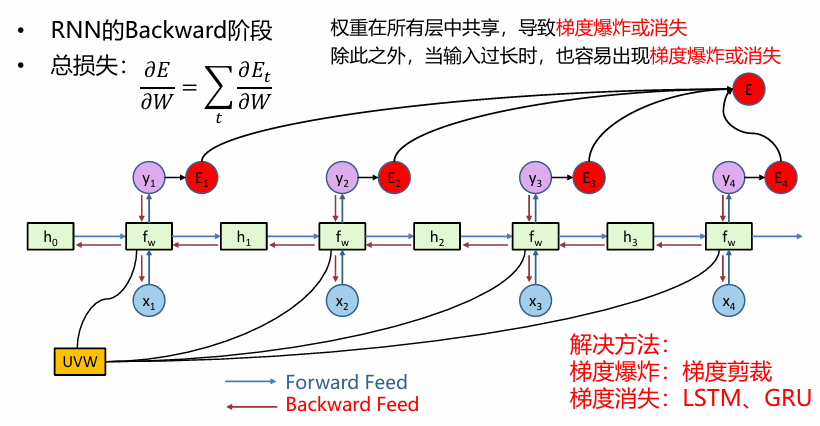
特点
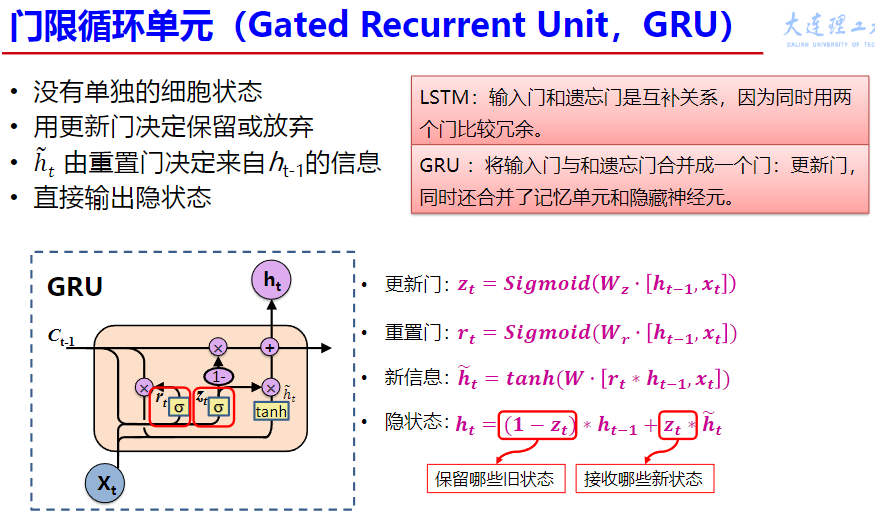
时序性、递归性:一般输入来自两个方面,$一个是之前状态 h_{t-1},和当前状态的输入x_t $。 参数共享:每一步的参数矩阵都是共享的,主要的参数矩阵也是上述的两个方面,W 和 U 。 cell的设计:为了解决RNN更新时指数式的梯度消失,梯度爆炸的问题和控制 cell 保留信息比例的问题,设计了GRU,LSTM cell
循环神经网络只能记住短期存储序列
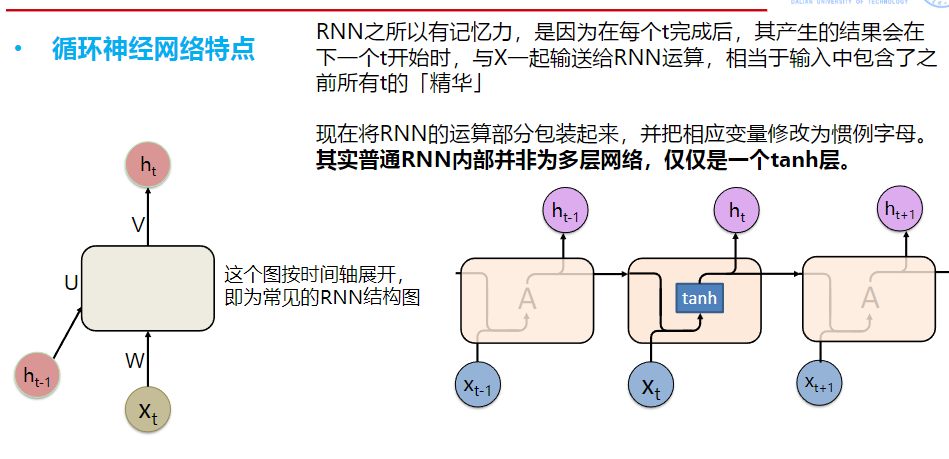
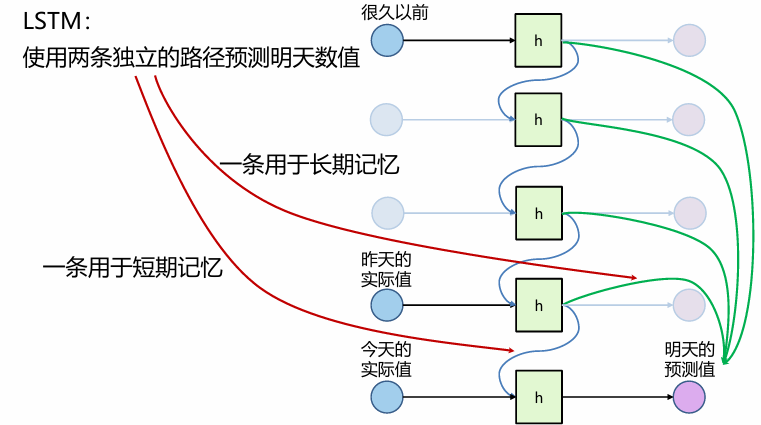
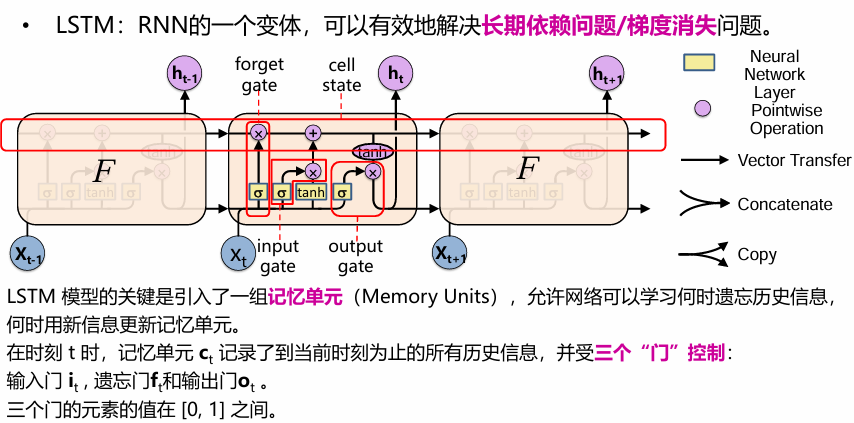
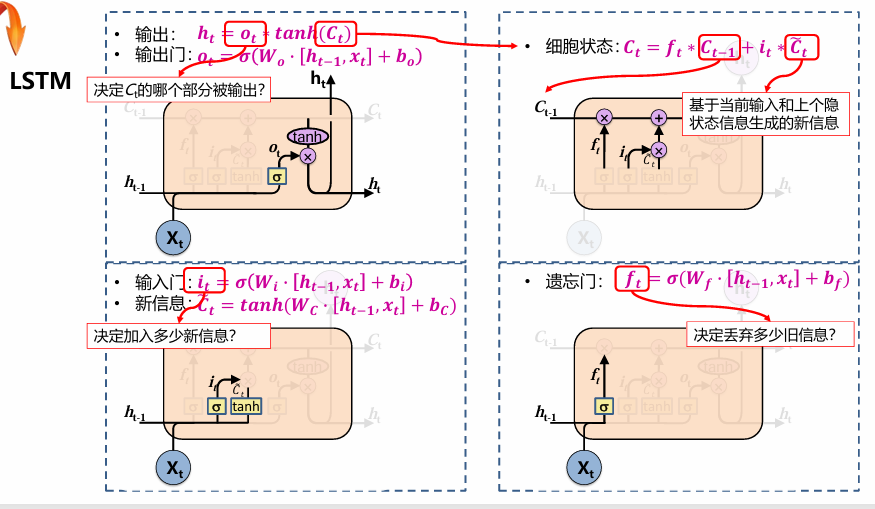
LSTM
长期依赖问题
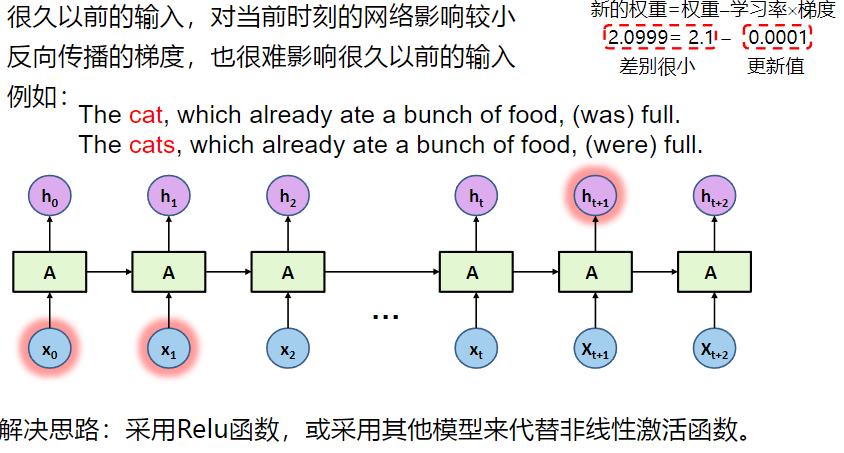
基本内容
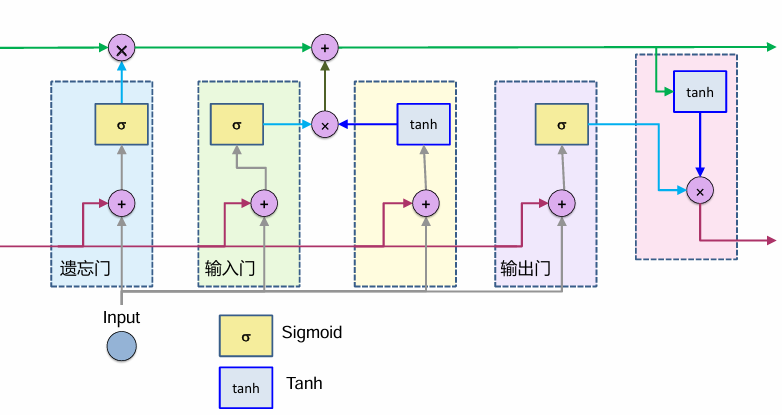
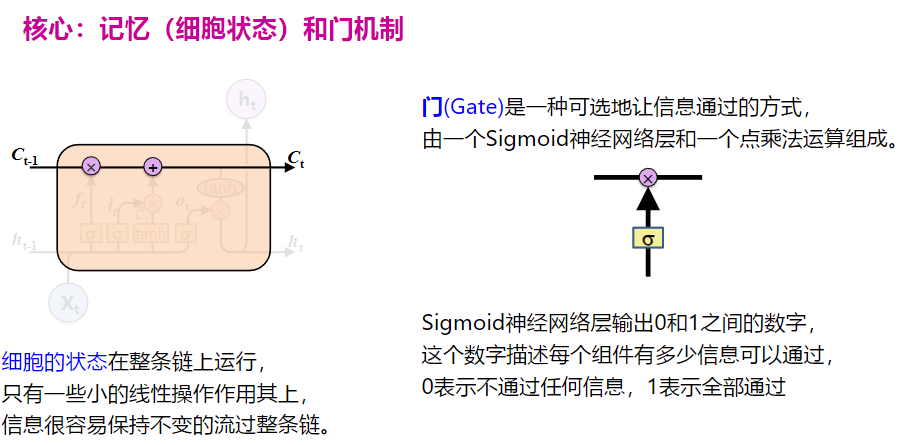
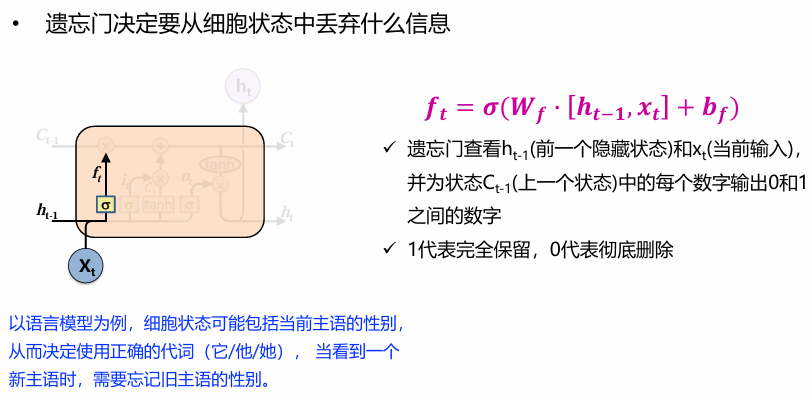
遗忘门
输入门

更新门

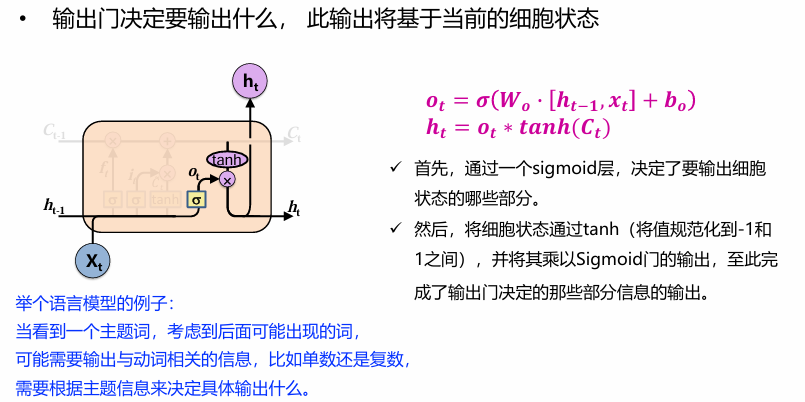
输出门
总结
有单独的细胞状态 用输入门和遗忘门决定保留或放弃 新信息 ሚ𝐶𝑡 来源于ht-1和xt 输出门控制细胞状态的输出 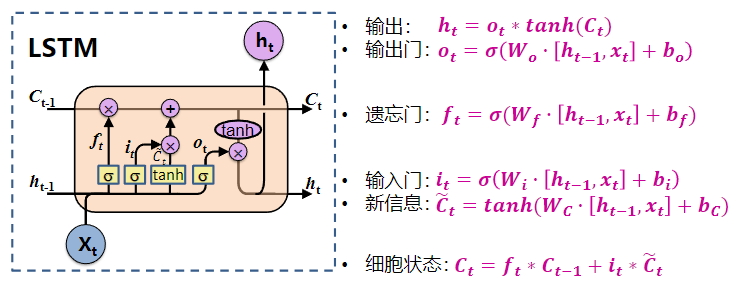
GRu
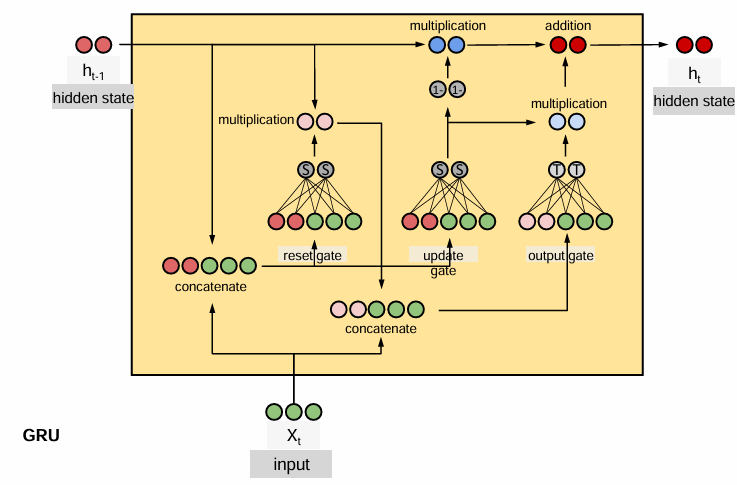
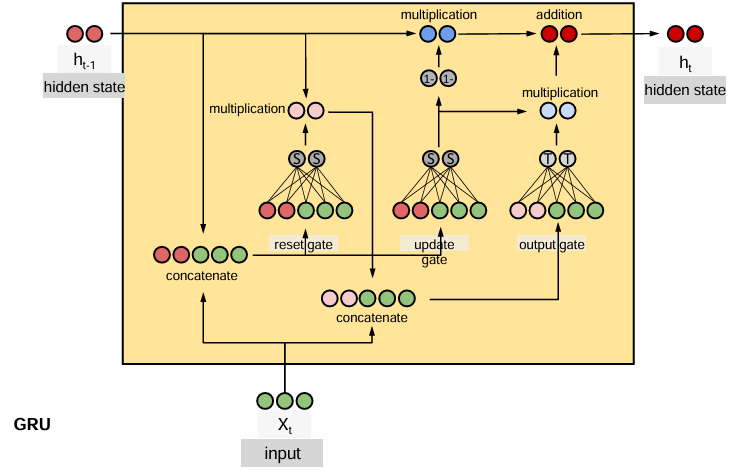
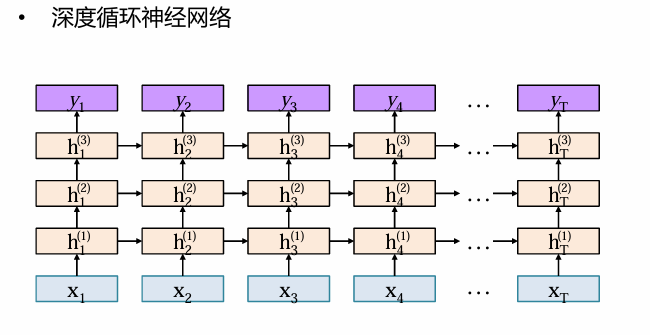
堆叠RNN
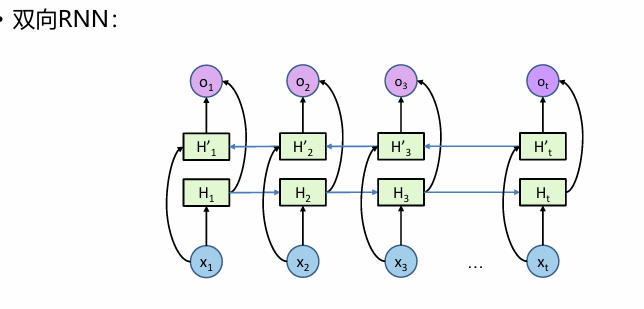
双向RNN
习题










